Cet article sur la performance des modèles d’IA s’inspire du contenu d’une série de 4 webinars gratuits sur l’intelligence artificielle et les LLM : l’IAcadémie proposée par le média Tribes. Ces formations s’appuient notamment sur notre expérience en IA au sein de la scale-up française Partoo qui développe divers produits dans ce domaine.
Les LLM, comme GPT-4, Mistral, ou LaMDA s’appuient sur une architecture complexe, entrainée grâce à l’ingestion d’une quantité massive de données textuelles : c’est ce qu’on appelle le pre-training ou pré-entrainement. S’en suivent ensuite les étapes d’ajustement et de renforcement que j’aborde dans un autre article de Tribes – à retrouver en suivant ce lien.
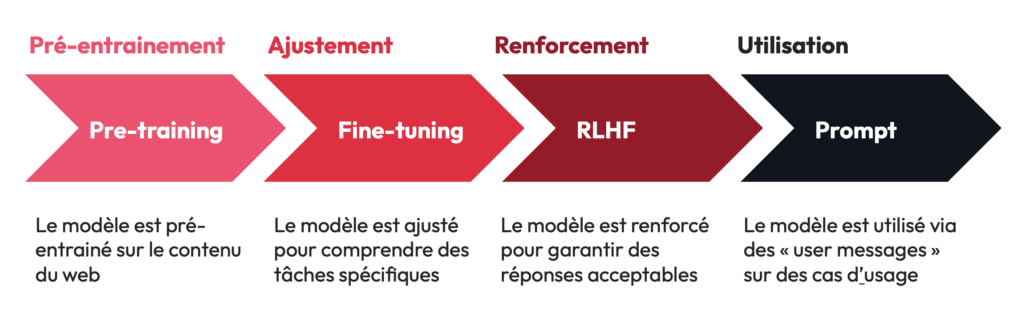
I) Qu’est-ce que le pré-entrainement ?
Le pré-entraînement des LLM ou « pre-training » peut être comparé à l’apprentissage chez les êtres humains. Un enfant apprend en écoutant son entourage, en répétant ce qu’il entend, et en formulant progressivement ses propres phrases. Cette écoute active permet à l’enfant de comprendre les concepts, les structures grammaticales et d’apprendre à interagir de manière cohérente avec son environnement.
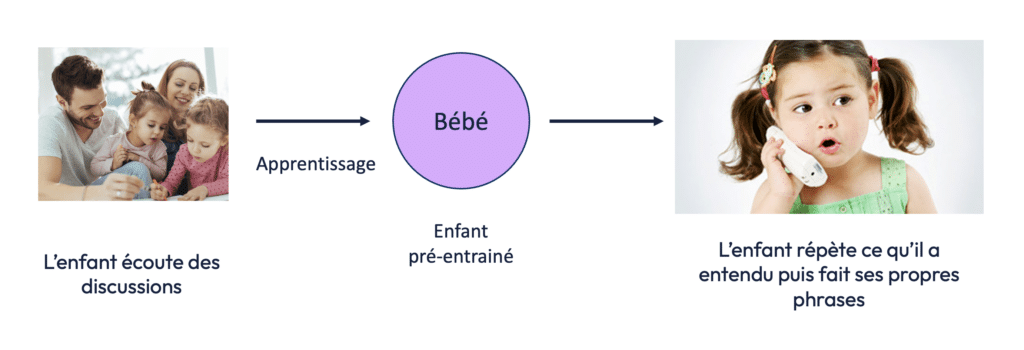
De la même manière, un LLM “écoute” des données textuelles en ingérant des milliers de milliards de mots provenant de diverses sources telles que Wikipédia, Reddit, ou encore des blogs. Ce processus d’apprentissage, appelé pré-entraînement, est fondamental pour que le modèle acquière une compréhension du langage naturel. Par exemple, GPT-4 a été entraîné sur l’équivalent de 100 000 ans de lecture humaine, un volume inimaginable pour l’esprit humain mais nécessaire pour qu’un modèle puisse répondre avec précision aux questions complexes des utilisateurs.
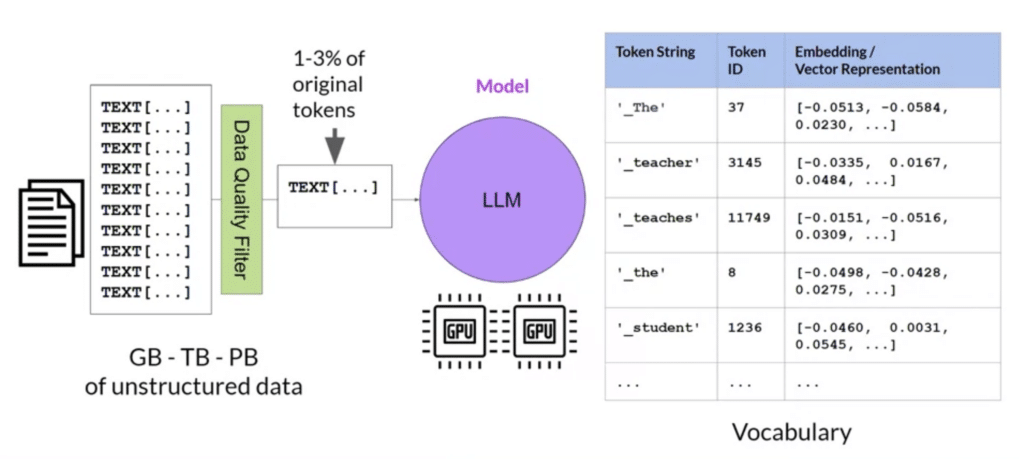
Le processus de pré-entraînement repose donc sur l’ingestion d’une énorme quantité de texte, qui permet aux modèles d’apprendre la structure des langues et les relations sémantiques entre les mots. Si vous souhaitez mieux comprendre comment les machines « comprennent » les mots, je vous invite à lire cet article Tribes qui traite de ce sujet, en particulier de la vectorisation des mots et des modèles Transformers.
II) Les trois facteurs de performance d’un LLM
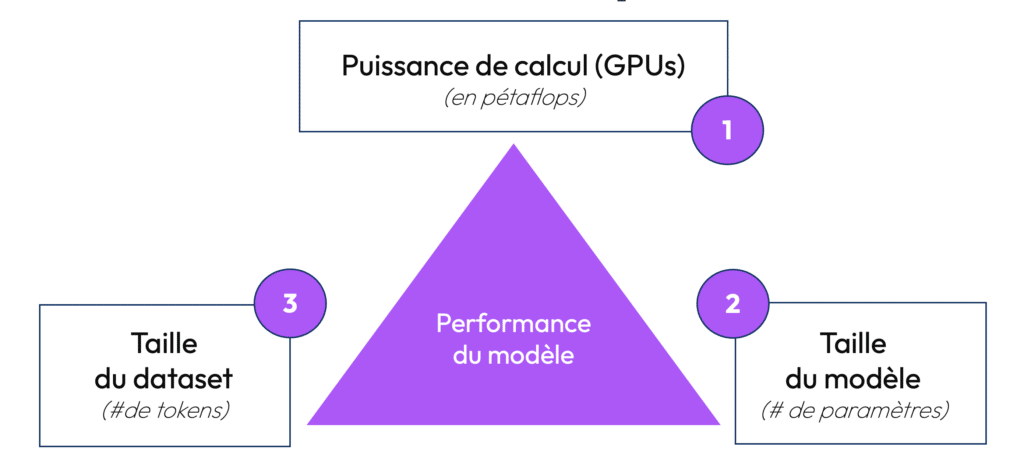
Dans cet article, nous allons nous concentrer sur le pré-entrainement et les facteurs qui déterminent la « performance » d’un modèle d’IA à savoir : la puissance de calcul, le nombre de paramètres, et la taille du dataset.
1) La Puissance de Calcul : Le traitement de la donnée
Le premier facteur limitant de la performance d’un modèle est lié à la puissance de calcul mis à sa disposition. Durant sa phase d’entrainement, un modèle d’IA est entraîné sur un système composé de GPU (unités de traitement graphique), capable de traiter de nombreuses tâches en parallèle – contrairement aux CPU traditionnels (les micro-processeurs) qui fonctionnent de manière plus séquentielle.
La puissance de calcul nécessaire à l’entrainement d’un LLM se mesure en PetaFlops (quadrillions d’opérations à virgule flottante par seconde). Pour vous donner une idée, un modèle comme GPT-4 utilise plusieurs milliers de GPU travaillant en parallèle. Cela génère une quantité d’opérations de traitement gigantesque, chaque calcul étant crucial pour affiner le modèle et améliorer sa précision.
Les GPU utilisés pour entraîner GPT-4 sont capables de traiter l’équivalent de 10 à 15 PetaFlops. Au fil du temps, la puissance de calcul est devenue un facteur limitant dans le développement des LLM, en raison de ses coûts énergétiques et financiers. L’entraînement d’un modèle comme GPT-3 a par exemple consommé l’équivalent de la consommation électrique annuelle de 1 000 foyers.
2) Le Nombre de Paramètres : La complexité du modèle
Le deuxième facteur critique dans la performance d’un LLM est le nombre de paramètres du modèle. Mais qu’est-ce qu’un paramètre ?
Les LLM s’appuient sur du Deep Learning, une forme d’intelligence artificielle qui repose sur des couches de neurones formant un réseau similaire à celui du cerveau – si vous avez besoin de mieux comprendre les liens entre IA, Machine Learning et Deep Learning, vous pouvez vous référer à cet article du média Tribes.
Dans un réseau de neurones, les paramètres représentent les connexions ajustables entre les différentes couches de neurones, qui permettent au modèle de mieux comprendre les relations complexes entre les mots, les phrases et les concepts. Un paramètre est, en quelque sorte, une “connexion pondérée” entre deux neurones.
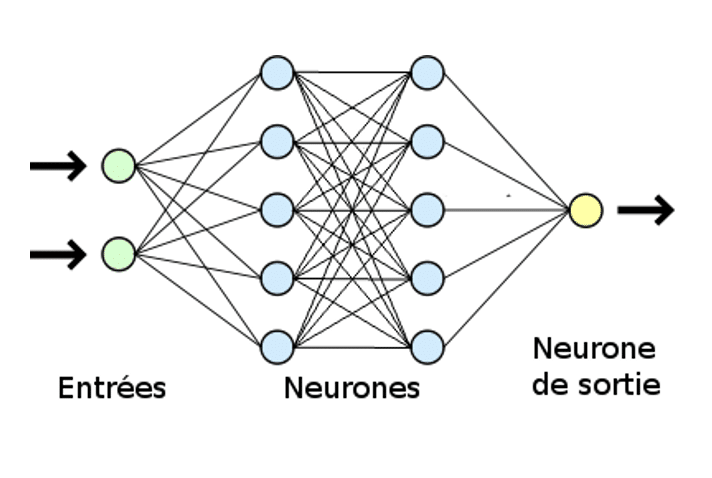
Un modèle avec peu de paramètres sera capable de comprendre des relations simples et d’exécuter des tâches basiques. Par exemple, un LLM avec 1 milliard de paramètres sera suffisant pour effectuer des tâches comme l’analyse de sentiment (déterminer si une phrase est positive ou négative). En revanche, un modèle avec 10 milliards de paramètres sera en mesure d’exécuter des instructions plus complexes, comme un chatbot capable de répondre à des commandes – ce que nous proposons chez Partoo. Enfin, des modèles plus complexes, comme GPT-4 avec 1 760 milliards de paramètres, peuvent accomplir des tâches de plus en plus sophistiquées !
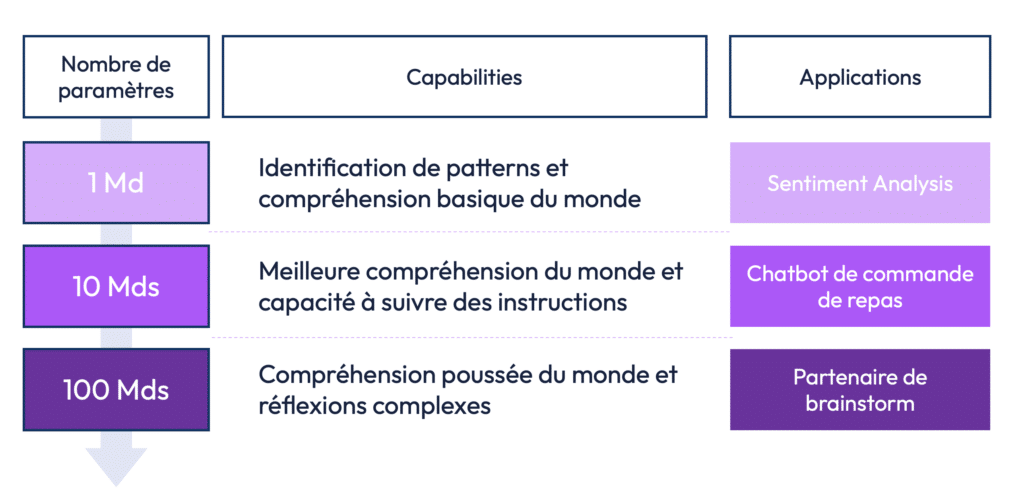
Cependant, augmenter le nombre de paramètres n’est pas sans conséquences. Plus le modèle a de paramètres, plus il consomme de ressources (GPU et énergie), et plus il nécessite un dataset volumineux pour être efficace.
3) La Taille du Dataset : La Base de Connaissance
Le troisième facteur limitant dans la performance d’un LLM est la taille du dataset d’entraînement. Un modèle, tout comme un enfant, a besoin d’un grand nombre d’exemples pour apprendre. Plus il est exposé à des données variées, mieux il pourra comprendre les subtilités du langage, les concepts abstraits et les nuances.
Un dataset est constitué de tokens, des unités de texte qui peuvent représenter des mots entiers ou des fragments de mots. Un modèle comme GPT-4 a été entraîné sur un dataset contenant des milliards de tokens, ingérés à partir de diverses sources, telles que des articles de presse, des blogs, des forums comme Reddit, et des livres numériques. La taille du dataset est importante, car elle permet au modèle de développer une compréhension globale du monde. Elle se mesure soit en nombre de token, soit en térabytes.
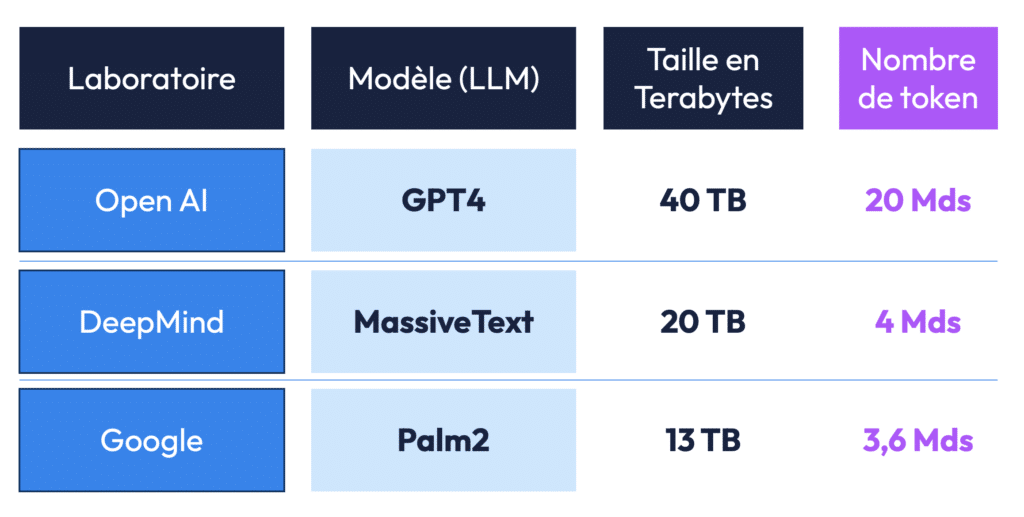
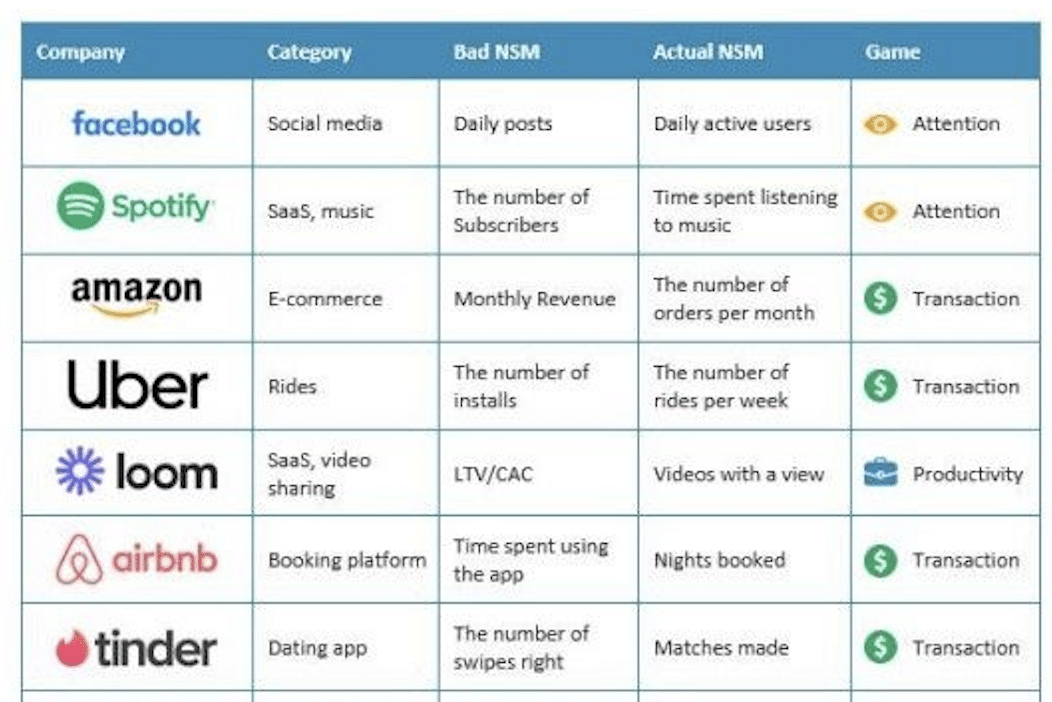
On a aussi découvert qu’il existe un équilibre optimal à respecter entre la taille du dataset et le nombre de paramètres, connu sous le nom de loi de Chinchilla. Cette loi explique que pour chaque augmentation du nombre de paramètres, il faut augmenter proportionnellement la quantité de données d’entraînement. Sinon, le modèle ne sera pas en mesure d’exploiter pleinement ses capacités, limitant ainsi sa performance. C’est ce que l’on retrouve dans le tableau ci-dessous qui présente le nombre de token optimal de certains modèles, comparés au nombre de token réels – mettant en évidence les datasets trop limités de certains modèles au regard de leur nombre de paramètres.

III) Optimisation des modèles
En raison des contraintes énergétiques que nous mentionnions plus haut, de nouvelles techniques d’optimisation des modèles ont vu le jour pour réduire leur consommation tout en maintenant des performances élevées. L’idée est souvent de jouer avec les paramètres du modèle qui induisent sa consommation énergétique. Parmi ces techniques, on retrouve :
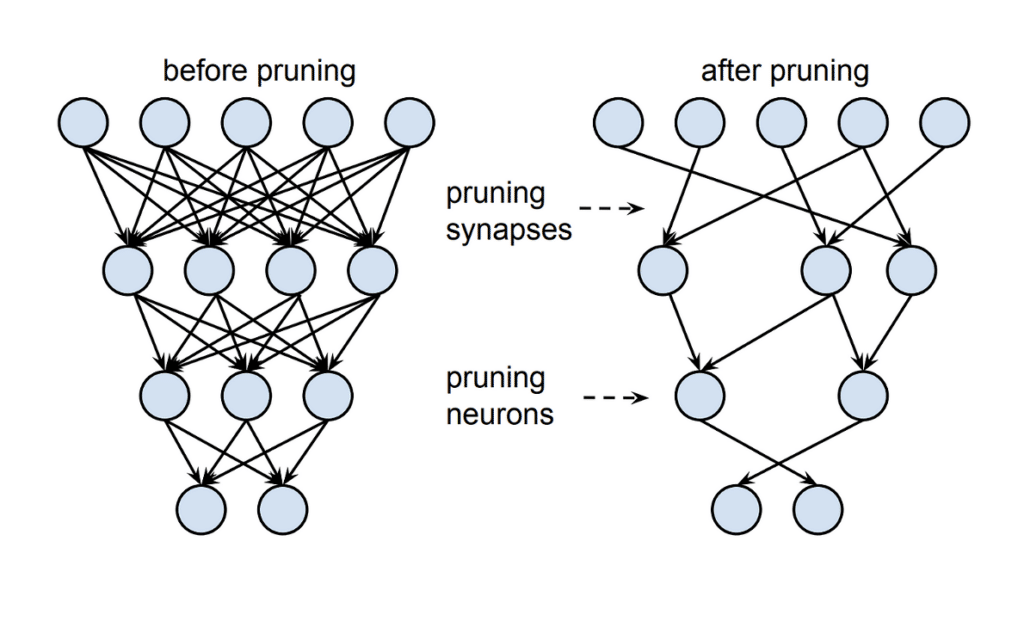
a) Le Pruning
Cette technique consiste à supprimer les paramètres inutiles du modèle sans forcément affecter ses performances. Cela permet de rendre le modèle plus léger et de réduire la puissance de calcul nécessaire à son fonctionnement.
b) La Quantification
Il s’agit ici de réduire la taille des paramètres en les représentant de manière plus compacte, optimisant ainsi les ressources nécessaires au traitement.
c) La méthode LoRA (Low-Rank Adaptation)
Cette technique permet de diminuer la complexité des modèles tout en maintenant des performances acceptables pour des tâches spécifiques. N’hésitez pas à vous référer à des articles dédiés pour mieux comprendre ce procédé !
Une tendance du marché est au développement de modèles plus petits, comme Feret d’Apple (qui fonctionne avec seulement 10 milliards de paramètres) ou Mistral AI (39 milliards de paramètres). Les modèles allégés présentent deux avantages majeurs : une réduction des coûts énergétiques et la possibilité de fonctionner sur des téléphones mobiles, sans avoir besoin d’être hébergés dans le cloud.
IV) Les Fournisseurs de Cloud
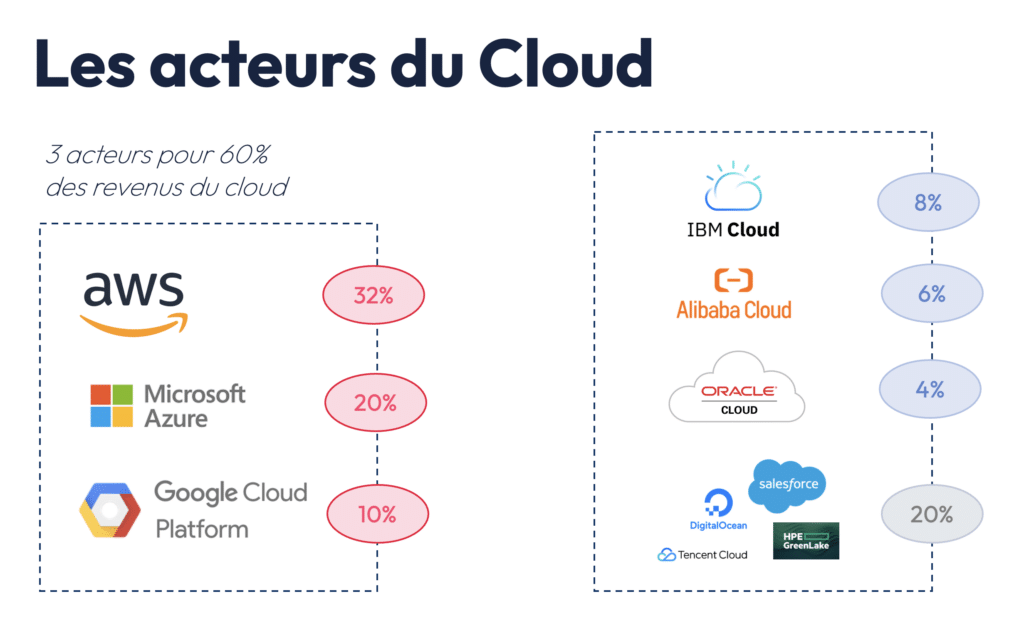
Pour finir cet article, je souhaitais enfin évoquer l’écosystème des fournisseurs de cloud. En effet, la plupart des entreprises qui déploient des LLM dépendent des fournisseurs de cloud, tels que AWS, Microsoft Azure, ou Google Cloud (GCP). Ci-dessous, j’ai détaillé les parts de marché de chaque acteur. Par exemple, chez Partoo, nous utilisons les modèles fondation d’Open AI sur Azure (Microsoft).
Ces géants du cloud offrent non seulement l’infrastructure pour héberger et entraîner les modèles, mais aussi des services sous forme d’API pré-packagées pour des tâches spécifiques, comme la reconnaissance d’images ou la prédiction de texte.

Chaque fournisseur de cloud développe donc des services et des plateformes qui construise un écosystème pour construire et déployer vos modèles d’IA. A toutes fins utiles, je vous ai détaillé ci-dessous quelques termes à connaitre de ces différents écosystèmes.
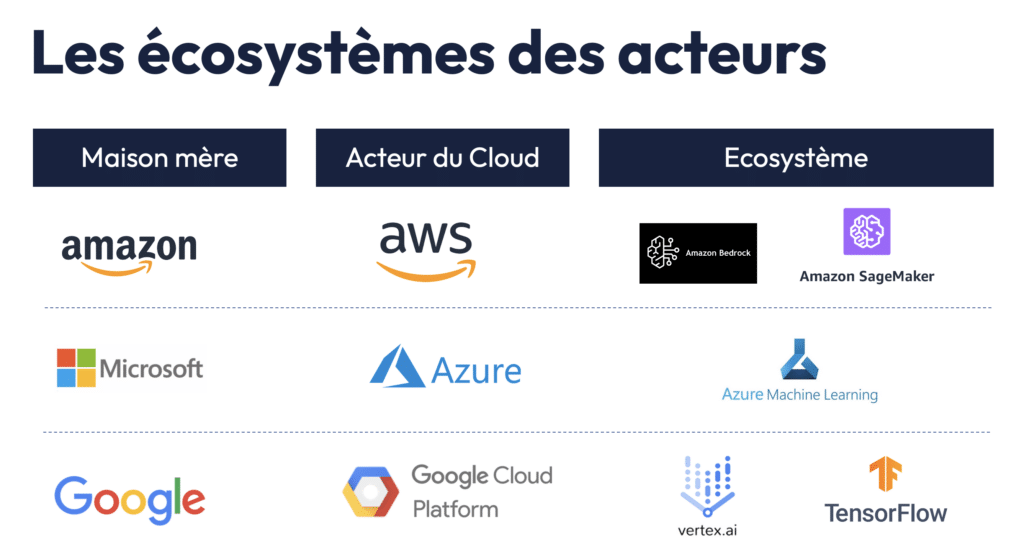
A noter qu’il est souvent inefficace d’utiliser un seul modèle pour toutes les tâches. Une approche multimodèle est souvent plus judicieuse, où plusieurs LLM plus petits et spécialisés sont déployés pour répondre à des besoins précis, maximisant ainsi l’efficacité tout en réduisant les coûts. En parallèle, l’utilisation de modèles open-source et la possibilité d’entraîner des modèles en local (on-premise) se développent, offrant plus de flexibilité aux entreprises.
Dans les années à venir, il est probable que nous verrons de plus en plus de modèles spécialisés et optimisés, capables de répondre à des besoins spécifiques avec des ressources réduites.
Si vous souhaitez mieux comprendre tous ces sujets, je vous invite à visionner la série de webinars IAcadémie dont vous trouverez les replays sur Youtube en suivant ce lien. Cette initiative bénévole a pour objectif de partager ce que nous avons appris sur l’IA en l’utilisant au sein des produits que nous développons chez Partoo à destination des retailers.