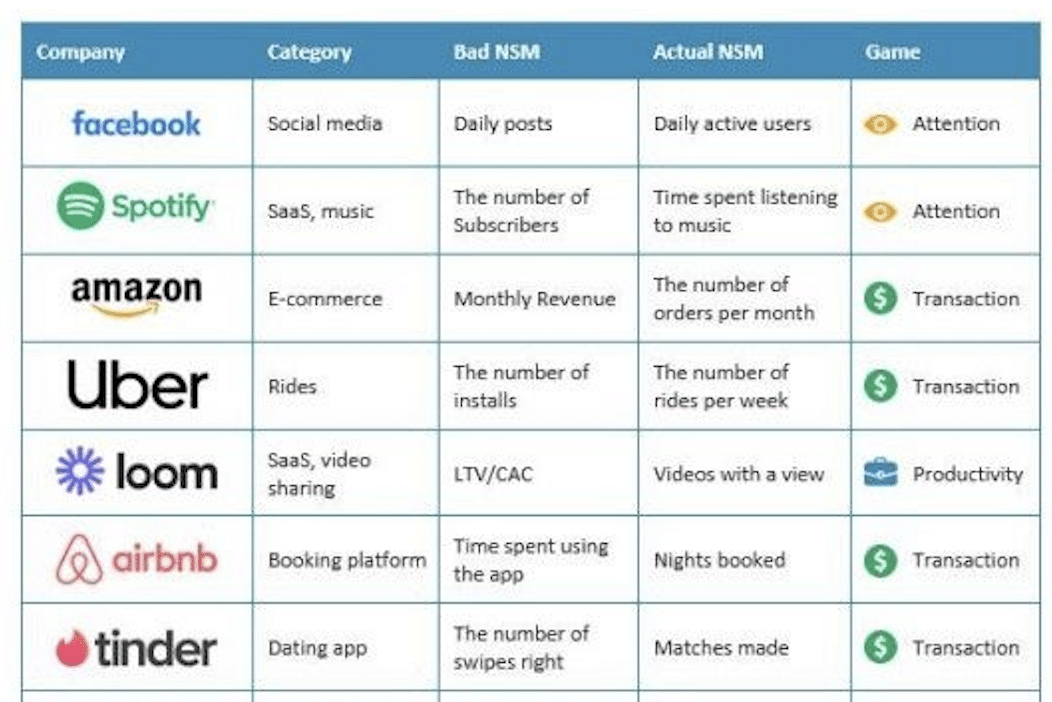

Cet article s’inspire d’une série de webinars sur l’IA disponible gratuitement sur Youtube : l’IAcadémie.
Chez Partoo, nous développons de nombreuses fonctionnalités en nous appuyant sur l’intelligence artificielle, qu’il s’agisse de Machine Learning ou d’IA générative. C’est dans ce contexte que j’ai décidé de me former sur ce sujet et de partager mes apprentissages sous la forme de webinars et d’articles.
Dans cet article, nous explorerons en détail les différents éléments qui composent un prompt (system et message user, shots…) ainsi que les paramètres qui définissent sa créativité et le risque d’erreur associé dans des applications réelles telles que la gestion des avis clients chez Partoo.
Qu’est-ce qu’un prompt ?
Un prompt est une entrée textuelle donnée à un modèle d’IA pour produire une réponse ou une action spécifique. Cette réponse peut être un texte, une prédiction, ou même un acte opérationnel. Par exemple, une question simple comme “Qui est le président de la France ?” ou une instruction plus complexe comme “Analyse cet avis client et détermine s’il est positif ou négatif” sont toutes deux des exemples de prompts.
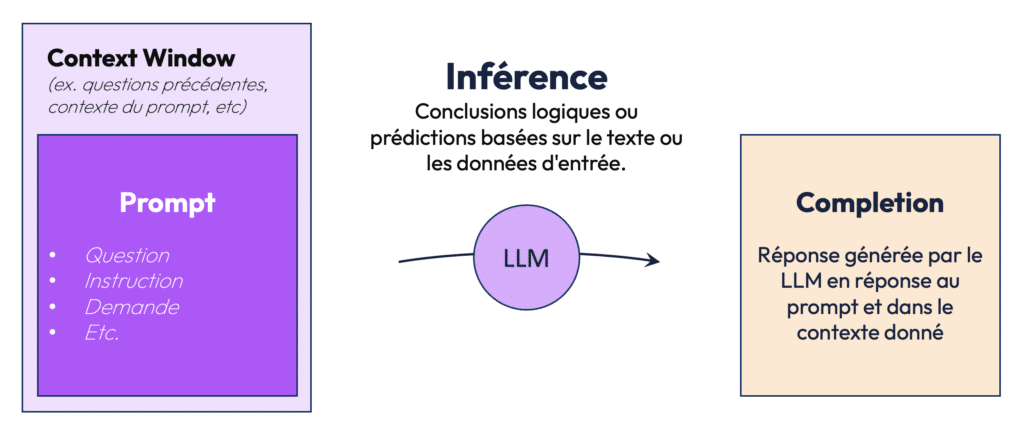
Le modèle d’IA utilise ces prompts pour générer ce que l’on appelle une complétion, c’est-à-dire la réponse au prompt. L’objectif du prompt engineering est donc de concevoir les meilleurs prompts possibles pour guider le modèle vers des réponses pertinentes. Ce processus est à la base de l’interaction avec les LLM tels que GPT-3, ChatGPT ou d’autres systèmes d’IA générative.
Comprendre le prompt engineering
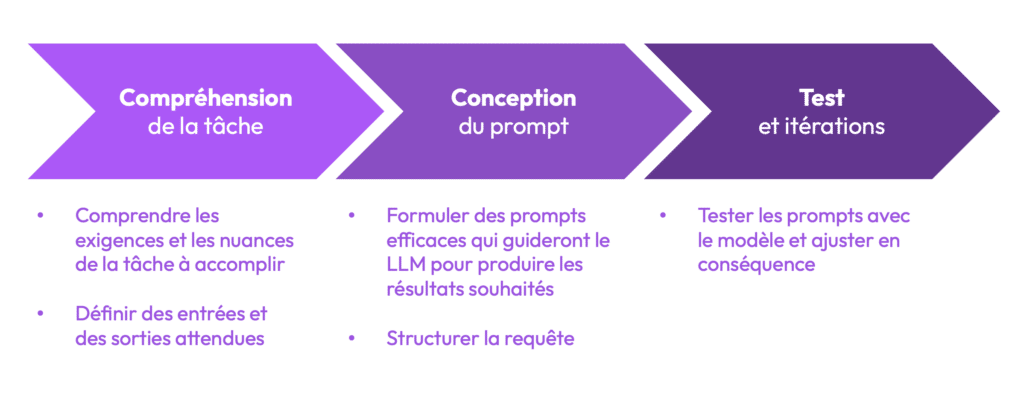
Le prompt engineering n’est pas nécessairement une discipline purement technique. Elle se concentre surtout sur la conception de questions claires, bien structurées et efficaces pour guider un modèle d’IA. Le travail consiste à formuler des requêtes d’une manière qui permet à l’IA de comprendre ce qui est attendu, puis d’itérer ces prompts en fonction des résultats obtenus. Ce processus suit trois grandes étapes :
- Comprendre la tâche : Il est essentiel de bien cerner les attentes et les nuances de la tâche que l’on souhaite que le modèle accomplisse.
- Concevoir le prompt : Une fois les attentes claires, la formulation d’un prompt doit être simple, précise, et contextualisée.
- Tester et itérer : L’amélioration continue repose sur des cycles de tests répétés pour affiner la formulation et obtenir les réponses les plus exactes possible.
Ces trois étapes sont la base d’une bonne utilisation des LLM dans différents contextes professionnels et personnels.
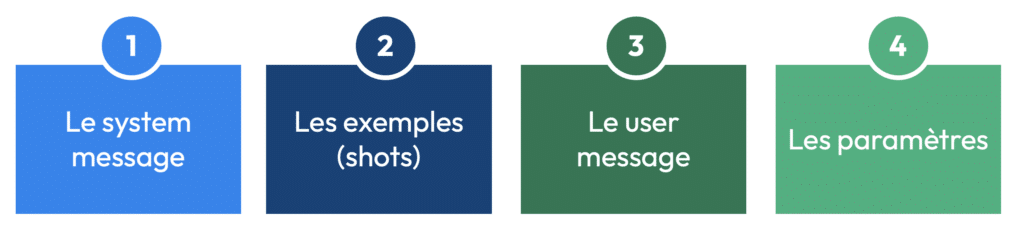
Structure d’un prompt : Les quatre blocs essentiels
Pour bien exploiter la puissance d’un LLM, il est crucial de comprendre la structure d’un prompt, qui repose sur quatre éléments principaux :
- Le système message
- Les shots
- le user message
- les paramètres
1. Le System Message
Le système message est une instruction donnée au modèle pour fixer un cadre dans lequel il doit opérer. Ce message permet de définir le rôle que le modèle doit jouer ou les règles qu’il doit suivre. Par exemple, vous pourriez dire à un modèle :
“Vous êtes Victor Hugo, répondez à cette question dans son style littéraire.”
Cela contraint le modèle à répondre dans le style de l’écrivain.
Prenons l’exemple de Partoo.
Dans le cadre de notre activité, nous avons développé une interface permettant aux points de vente et aux réseaux de points de vente de répondre aux avis de leurs clients sur Google Maps. Etant donné que certaines enseignes comme Castorama ou Toyota ont des milliers d’avis en ligne sur Google Maps, cela peut prendre du temps.
Nous avons donc développé une fonctionnalité d’IA permettant à nos clients de générer une suggestion de réponse par IA à un avis donné.
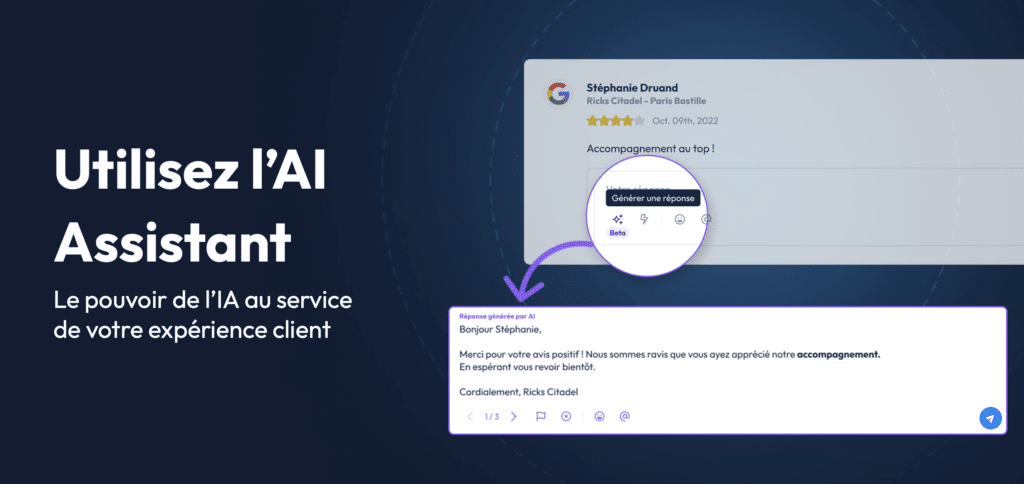
Pour se faire nous avons utilisé le System Message suivant : “Vous êtes le propriétaire d’un restaurant, et vous devez répondre aux avis clients de manière polie et professionnelle.” Cela guide l’IA pour qu’elle adapte son ton et ses réponses à un cadre précis.
Quelques bonnes pratiques pour créer un bon système message incluent :
- Le role-playing : Définir le rôle que doit jouer l’IA (expert, personnage fictif, etc.).
- Le contexte : Fournir des informations précises pour guider la réponse du modèle.
- Les contraintes de sortie : Définir ce que vous attendez comme réponse et les limites de cette réponse (ex. : ne pas proposer de promotions ou de fausses promesses).

2. Les shots
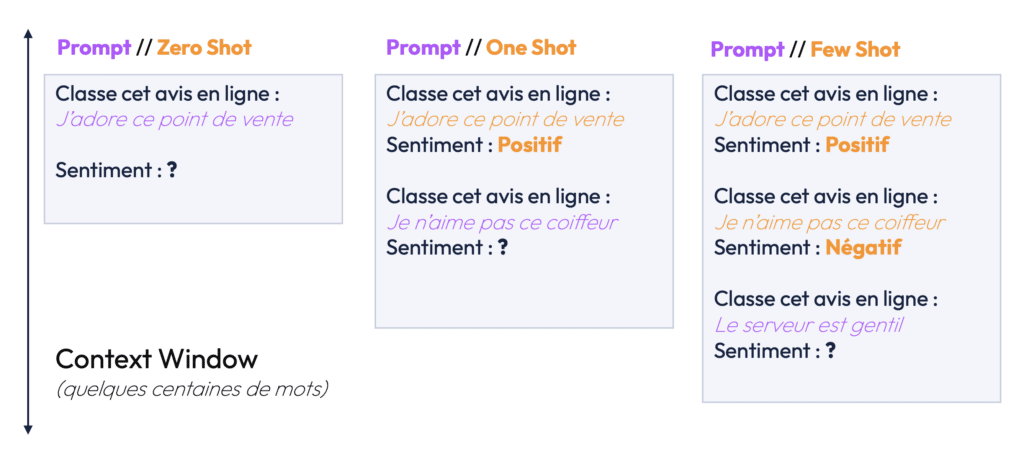
Les shots sont des exemples que vous fournissez à l’IA pour lui montrer comment elle doit répondre à des situations spécifiques. Chaque shot se compose d’un couple prompt-completion, c’est-à-dire d’un exemple de question ou d’instruction et d’une réponse ou d’une action attendue. Ces exemples permettent au modèle de mieux comprendre les attentes en lui donnant des références concrètes.
On parle souvent de zero-shot, one-shot ou few-shot prompting selon le nombre d’exemples fournis au modèle. Le few-shot prompting est particulièrement utile lorsque vous voulez influencer l’IA pour qu’elle suive un certain type de comportement ou style de réponse, en lui fournissant plusieurs exemples de qualité.
Chez Partoo, par exemple, les shots pourraient être des exemples d’avis clients sur Google Maps et des réponses satisfaisantes à ces avis. L’IA apprend à partir de ces exemples pour mieux structurer ses futures réponses.
3. Le User Message
Le User Message correspond à la question ou à l’instruction donnée par l’utilisateur final. C’est l’élément déclencheur qui initie l’interaction avec le modèle d’IA.
Dans le cadre de notre exemple avec Victor Hugo, pour lequel le System Message était ““Vous êtes Victor Hugo, répondez à cette question dans son style littéraire”, le User Message pourrait être une question simple : “Décrivez la beauté de la nature.” L’IA va alors générer une réponse basée sur le système message et les exemples fournis.
Dans le cas de Partoo, le user message est l’avis client publié sur une plateforme comme Google Maps. L’IA doit prendre cet avis en entrée, l’analyser, et générer une réponse appropriée en fonction des autres éléments du prompt.
Les paramètres, quatrième déterminant du prompt
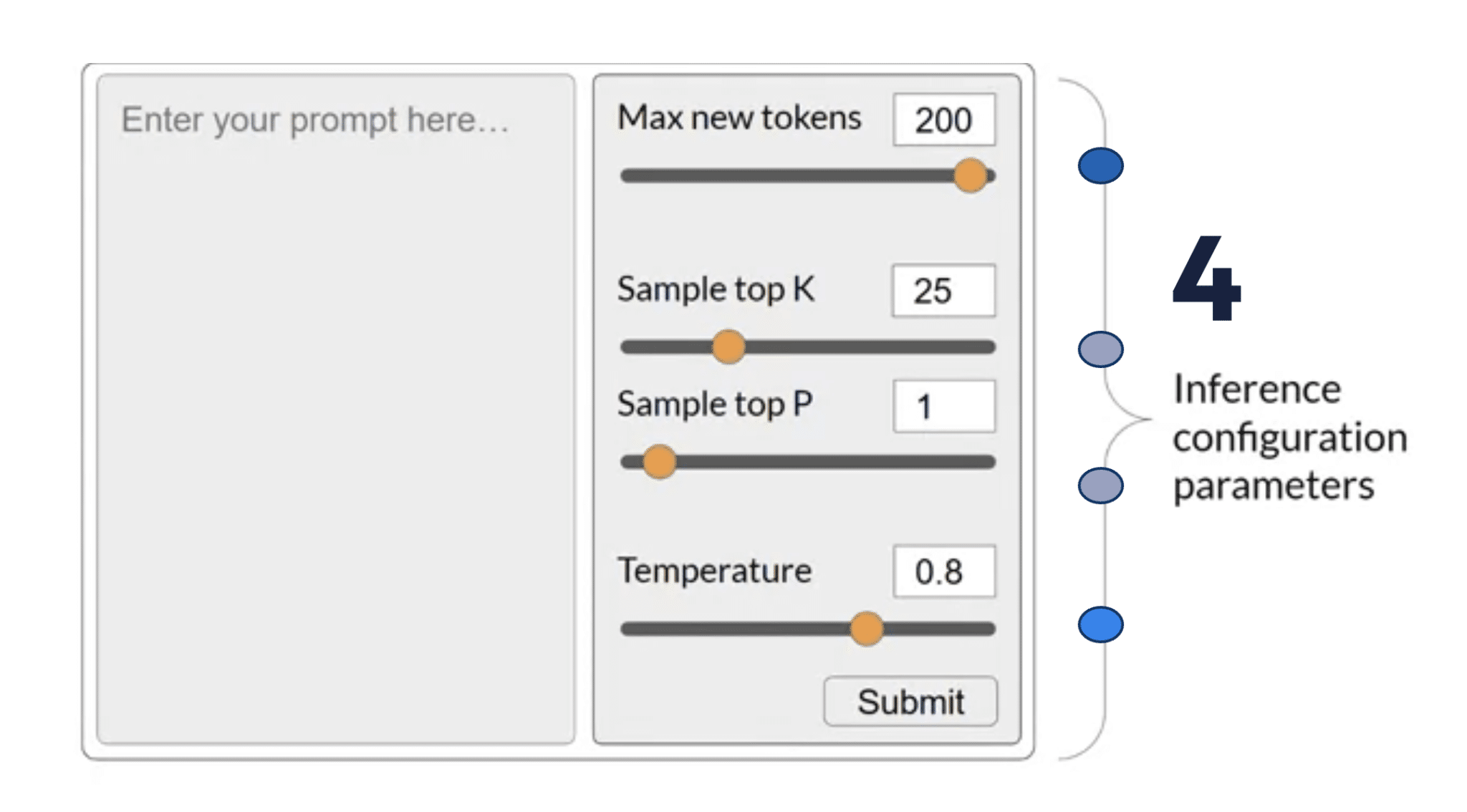
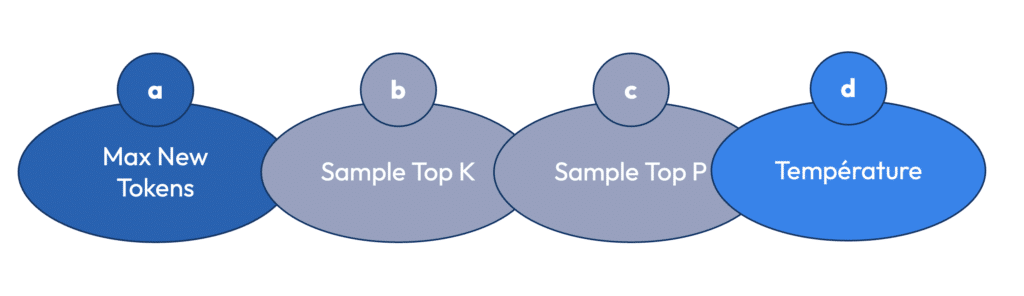
Les paramètres d’un prompt jouent un rôle crucial dans la manière dont un modèle d’IA va générer ses réponses. Ils influencent non seulement la longueur de la réponse, mais aussi sa créativité, sa cohérence et sa précision. Pour bien comprendre comment ajuster un prompt et tirer le meilleur parti d’un LLM (Large Language Model), il est essentiel de se familiariser avec les quatre paramètres principaux : Max new tokens, Sample top-K, Sample top-P, et Température.
a) Max new tokens
Le paramètre Max new tokens contrôle la longueur maximale de la réponse générée par le modèle. En termes simples, cela définit le nombre maximal de “tokens” (unités de texte) que l’IA est autorisée à produire dans sa réponse. Un token correspond à un mot ou une partie d’un mot, en fonction de la manière dont le modèle segmente le texte. Par exemple, des mots courants comme “chat” ou “table” peuvent être considérés comme un seul token, tandis qu’un mot plus complexe ou une série de lettres peut être décomposée en plusieurs tokens. Pour en savoir plus sur la manière dont un modèle d’IA comprend les mots (tokenisation & vectorisation), voici un article détaillé que j’ai écris sur le sujet.
La limitation du nombre de tokens est cruciale pour garantir que la réponse reste dans des limites acceptables, en particulier lorsque le texte généré est destiné à des interactions spécifiques comme des réponses aux avis clients.
Une autre raison de contrôler le nombre de tokens est liée aux limites techniques des LLM eux-mêmes. Chaque modèle a un maximum de tokens qu’il peut gérer à la fois, ce qui inclut à la fois l’entrée (le prompt) et la sortie (la complétion). Si cette limite est dépassée, le modèle ne pourra pas traiter la requête et la génération de texte sera interrompue.
b) Sample top-K
Le paramètre Sample top-K contrôle la manière dont le modèle sélectionne les mots pour construire une phrase. Lorsqu’un modèle d’IA génère une réponse, il ne choisit pas les mots de manière totalement aléatoire. Il choisit chaque mot, un par un, sur la base d’une probabilité définie par son entrainement, comme un auto-complete géant.
Chaque mot est donc attribué à une probabilité, qui dépend du contexte et des données sur lesquelles le modèle a été entraîné. Par exemple, si le modèle est en train de compléter la phrase “La souris est mangée par le…”, il est plus probable que le mot “chat” soit choisi plutôt que “requin” ou “pantalon”, en raison des connaissances communes intégrées dans le modèle.

Le Sample top-K limite le nombre de choix possibles parmi les probabilités calculées. Ce paramètre détermine combien de mots parmi les K meilleurs candidats le modèle est autorisé à sélectionner. Si K est réglé sur 3, par exemple, cela signifie que le modèle va choisir parmi les trois mots ayant les probabilités les plus élevées, en excluant les autres possibilités, même si elles sont moins probables mais tout de même viables. Cela permet d’éviter que le modèle ne choisisse des mots incongrus ou inattendus, ce qui est particulièrement utile dans des contextes où la cohérence est essentielle.
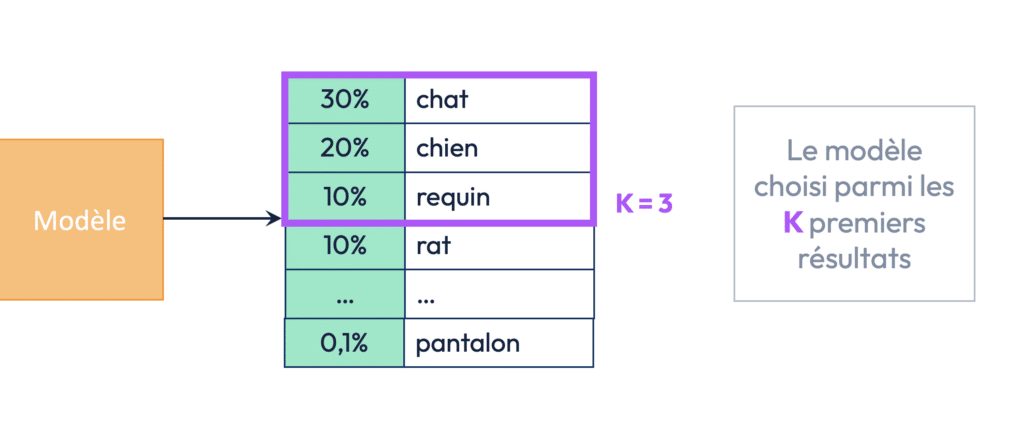
En réglant Sample top-K à un chiffre bas, vous forcez le modèle à se concentrer sur les choix les plus évidents, réduisant ainsi les risques de déviations ou de réponses absurdes. Cela permet d’améliorer la cohérence des réponses, mais cela peut aussi limiter la créativité de l’IA. Si au contraire vous augmentez la valeur de K, le modèle aura plus de liberté pour explorer des mots moins probables, ce qui peut générer des réponses plus variées et inventives, mais aussi plus susceptibles de contenir des erreurs ou des hallucinations.
c) Sample top-P (ou nucleus sampling)
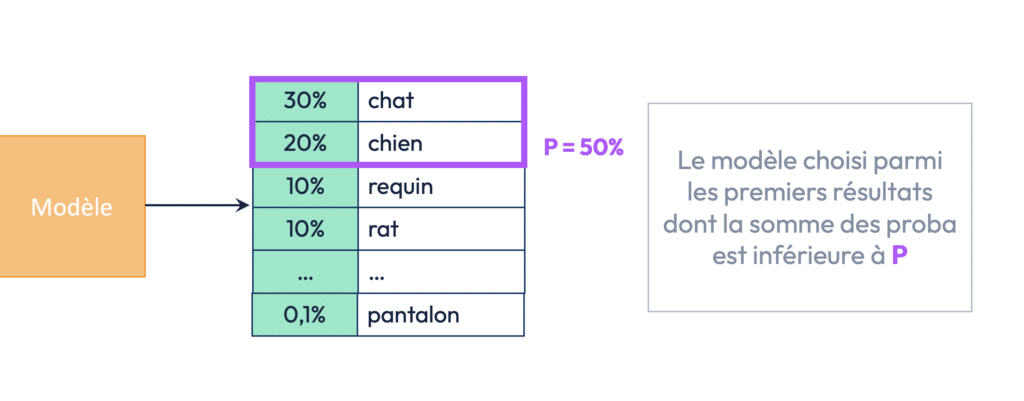
Le Sample top-P, également appelé nucleus sampling, est une méthode qui fonctionne de manière similaire à Sample top-K, mais avec une différence notable : au lieu de limiter le nombre de choix à un nombre fixe de mots (K), ce paramètre limite les choix aux mots dont la somme des probabilités atteint un certain pourcentage (P). Cela signifie que le modèle va choisir parmi les mots dont la somme des probabilités est égale ou supérieure à une valeur donnée (par exemple, 80 %).
d) Température
Le paramètre de température est probablement le plus crucial parmi les paramètres, car il affecte directement le degré de créativité et d’originalité de l’IA dans la génération des réponses. La température détermine à quel point le modèle “joue” avec les probabilités des mots pour choisir celui qui va apparaître ensuite dans la phrase. Plus la température est basse (proche de 0), plus le modèle sera conservateur et choisira les mots les plus probables. Plus la température est élevée (proche de 1), plus le modèle sera inventif et prêt à prendre des risques, en sélectionnant des mots moins probables.
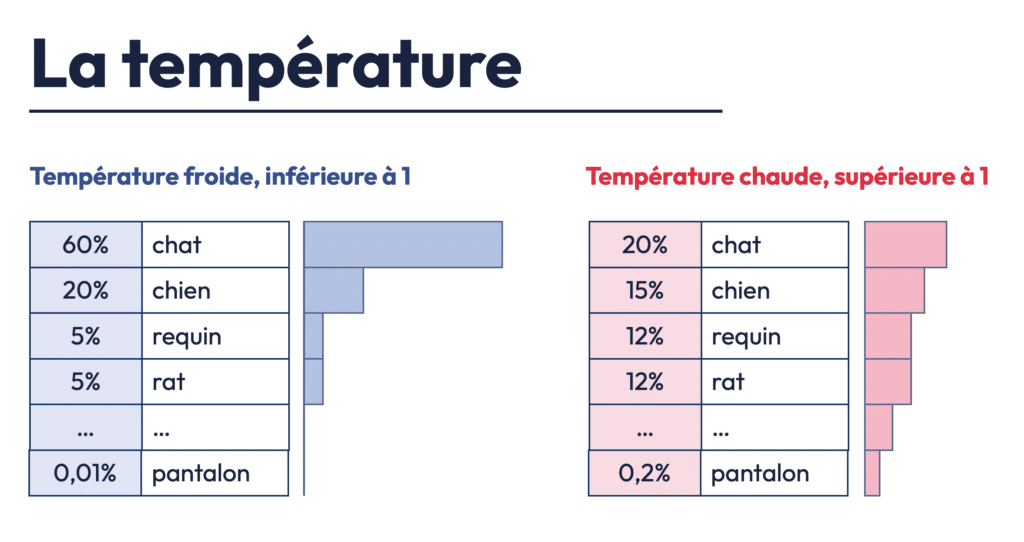
Avec une température basse, le modèle tend à privilégier les mots les plus prévisibles, ce qui peut générer des réponses précises mais parfois monotones ou répétitives. Cela peut être utile dans des situations où l’exactitude est essentielle, comme dans des prédictions financières ou des réponses techniques. En revanche, une température plus élevée permet au modèle de générer des réponses plus créatives et imprévisibles, ce qui peut être utile dans des contextes plus artistiques ou pour des tâches nécessitant une approche plus inventive, comme la rédaction de poèmes ou la génération d’histoires.
Par exemple, chez Partoo, lorsque l’IA est utilisée pour répondre aux avis Google, une température de 0,95 est généralement utilisée. Cela permet de maintenir un certain niveau de diversité dans les réponses tout en conservant une cohérence suffisante pour que les réponses restent pertinentes. Si la température était trop basse (par exemple 0,5), les réponses seraient certes correctes, mais elles pourraient devenir trop répétitives, avec des formules prévisibles. À l’inverse, une température trop élevée (par exemple 1,2) pourrait conduire à des réponses trop créatives, voire absurdes, en décalage avec le contexte.
Amélioration continue
L’IA de Partoo permettant de suggérer des réponses aux avis, se base sur les éléments du prompt, mais aussi sur des processus d’amélioration. Le fine-tuning consiste à ajuster l’IA en fonction des retours d’expérience pour affiner la qualité des réponses générées. Pour en savoir plus sur le fine-tuning et le RLHF, deux sujets passionnants, je vous invite à lire cet article Tribes complet sur le sujet.
Dans le cadre des suggestions de réponse aux avis, lorsque des erreurs ou des hallucinations surviennent (comme des offres promotionnelles non désirées ou des fausses promesses), l’IA est “corrigée” en ajustant les système messages ou en ajoutant des règles pour limiter ces comportements.
Une anecdote particulière permet de mieux comprendre ce processus d’amélioration continue : notre IA interprétait mal l’acronyme RAS et produisait des réponses incohérentes quand elle le rencontrait… Pour corriger cela, l’équipe Partoo en charge du projet a dû inclure une ligne spécifique dans le prompt expliquant ce que “RAS” signifie (“Rien à signaler). En réponse à ce changement, le modèle a commencé à utiliser cette acronyme à chaque fin de réponse ce qui a obligé l’équipe à ajouter une nouvelle ligne indiquant au modèle qu’il ne pouvait pas utiliser cet acronyme lui-même !
Bonnes pratiques en prompt engineering
Pour finir cet article, voici quelques bonnes pratiques pour améliorer la qualité des prompts que vous souhaitez utiliser :
- Utiliser des formulations positives : Il est préférable de donner des directives claires et positives. Par exemple, plutôt que de dire “N’utilise pas un langage familier”, dire “Utilise un langage formel”.
- Décomposer les tâches complexes : Il est souvent utile de scinder une tâche complexe en plusieurs sous-tâches simples. Cela permet au modèle d’IA de mieux structurer sa réponse.
- Poser des questions ouvertes : Plutôt que de tout préciser dès le départ, vous pouvez laisser l’IA poser des questions pour mieux cerner le besoin. Cela permet une interaction plus conversationnelle et personnalisée.
- Tester et itérer : La clé du prompt engineering réside dans l’amélioration continue. Il faut tester différents paramètres, analyser les résultats, et ajuster les prompts en fonction des performances observées.
Conclusion
Les prompts et les agents virtuels représentent un domaine fascinant de l’IA, avec des applications concrètes dans de nombreux secteurs. La clé pour exploiter tout leur potentiel réside dans la maîtrise des principes du prompt engineering, la compréhension des paramètres, et l’adoption d’une démarche d’amélioration continue.
Si vous souhaitez vous former plus généralement sur tous ces sujets, je vous invite à prendre quelques heures pour visionner nos formations gratuites sur l’intelligence artificielle à retrouver ici !