Ce premier article s’inspire du contenu d’un webinar introductif sur l’intelligence artificielle (IA), qui s’intègre dans un cycle de quatre sessions, chacune d’une durée approximative d’une heure. Il a pour objectif de présenter les bases de l’IA, vulgariser ses concepts et poser les fondations pour une compréhension approfondie des technologies d’apprentissage automatique (Machine Learning, ML), apprentissage profond (Deep Learning, DL), et IA générative.
Partie 1 : Introduction à l’IA, Machine Learning et Deep Learning
1.1 Contexte Historique et Évolution de l’IA
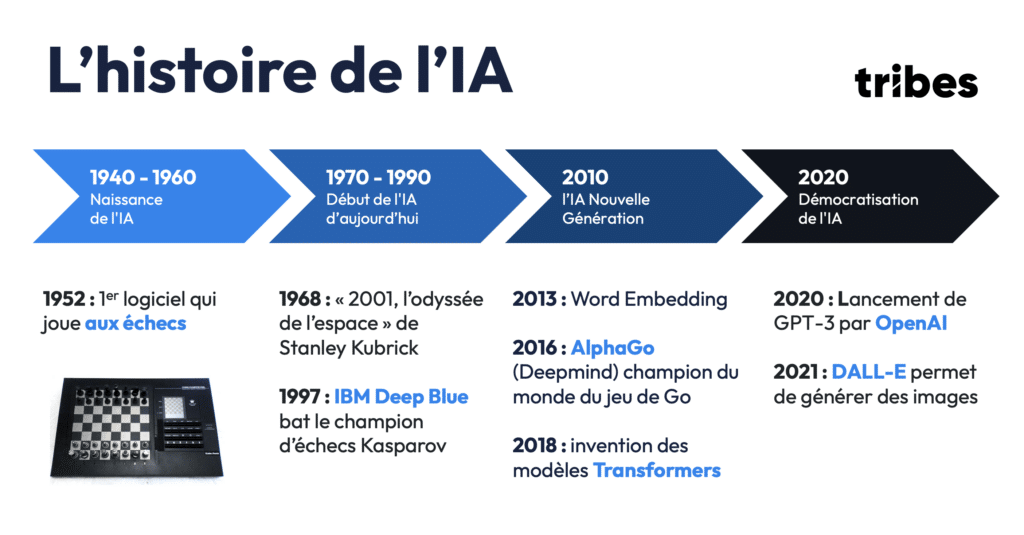
L’intelligence artificielle, aujourd’hui omniprésente dans nos vies, trouve ses origines dans les années 1950. À cette époque, les premiers programmes d’IA étaient des logiciels conçus pour accomplir des tâches très spécifiques, comme jouer aux échecs. L’IA restait limitée à des systèmes symboliques : les machines imitaient les décisions humaines à partir de règles définies.
–
–
Une étape marquante de cette première ère de l’IA a été la victoire d’IBM Deep Blue en 1997 contre le champion d’échecs Garry Kasparov, marquant un tournant dans la capacité des machines à surpasser les humains dans des tâches complexes.
Mais c’est à partir de 2010 que l’IA a connu une transformation profonde, avec l’émergence de deux innovations majeures : l’embedding de mots (Word Embedding) en 2013 et le modèle Transformer en 2018. Ces deux découvertes ont permis de surmonter les limites des IA basées sur des règles, introduisant des modèles d’apprentissage à partir de grandes quantités de données non structurées.
En 2020, l’IA entre dans une phase de démocratisation avec le lancement de GPT-3 par OpenAI, un modèle capable de générer du texte d’une cohérence surprenante. Ce modèle est représentatif des Modèles de Langage de Grande Taille (Large Language Models, LLM), une catégorie de systèmes IA capables de traiter et de générer du langage naturel.
1.2 Les Fondements de l’IA : Machine Learning, Deep Learning et IA Générative
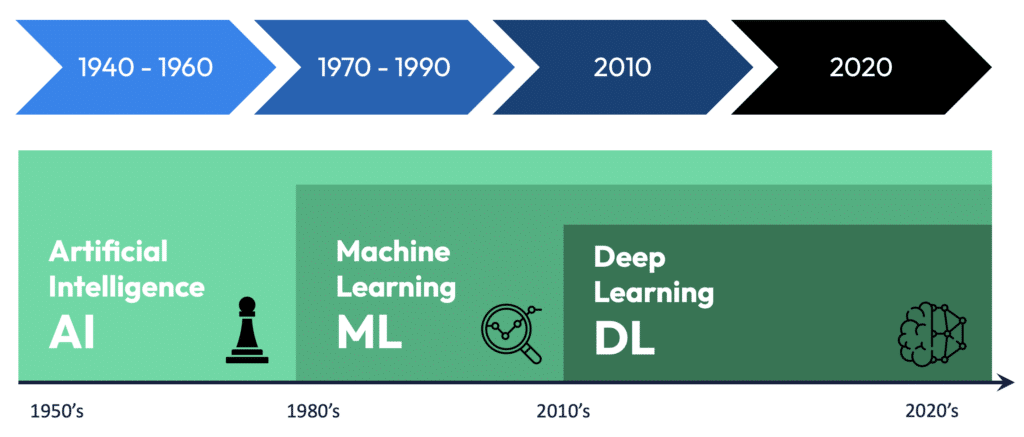
Pour mieux comprendre l’IA moderne, il est essentiel de distinguer trois concepts clés : l’intelligence artificielle (IA), le machine learning (ML), et le deep learning (DL). Ces trois termes sont parfois utilisés de manière interchangeable, mais ils se distinguent par leur portée et leur champ d’application.
–
–
A. L’intelligence artificielle
L’intelligence artificielle regroupe l’ensemble des systèmes capables de reproduire, imiter ou améliorer les capacités cognitives humaines. Cela englobe aussi bien les IA traditionnelles basées sur des règles que les systèmes d’apprentissage automatique.
B. Le machine learning
Le machine learning est un sous-ensemble de l’IA. Ici, la machine n’est plus explicitement programmée pour accomplir une tâche, mais apprend à partir d’exemples. L’apprentissage automatique repose sur l’analyse de données, souvent massives, pour en extraire des patterns et des règles implicites. Cette méthode est très puissante, car elle permet aux machines de s’adapter à de nouvelles données sans être reprogrammées manuellement.

Quand les animaux ou les humains apprennent, ils observent sur des exemples. De la même manière, dans le machine learning, l’IA n’apprend pas via des règles mais via des exemples. Pour décrire un feu rouge un algo classique va proposer des règles (ex. “trois feu, un rouge, un orange, un vert”) mais ces règles sont beaucoup trop simplistes. Au contraire, si on montre à un algorithme de machine learning des centaines de feux rouges, il déterminera des règles implicites.
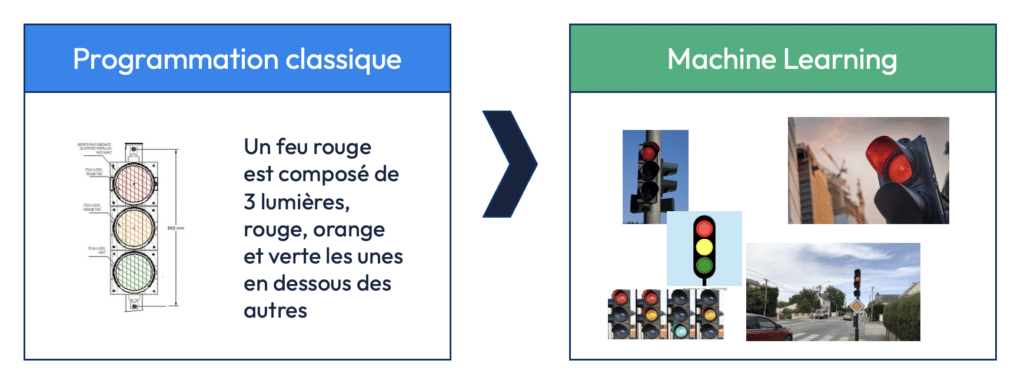
C. Le deep Learning
Le deep learning est une sous-catégorie du machine learning. Il repose sur des réseaux de neurones profonds, inspirés du fonctionnement du cerveau humain. Ces réseaux sont capables d’apprendre des représentations hiérarchiques des données, ce qui les rend particulièrement efficaces pour traiter des données complexes comme les images, les vidéos, et le langage naturel. Plus le réseau est profond, c’est-à-dire plus il contient de couches de neurones, plus il peut traiter des informations complexes.
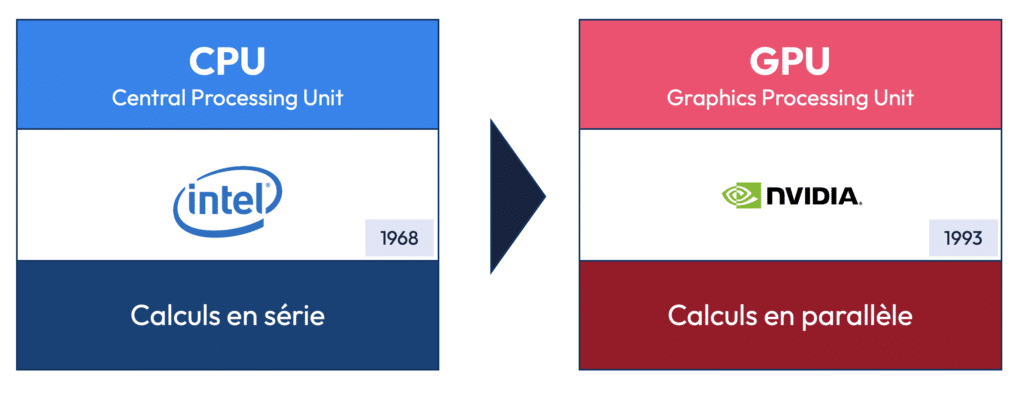
Le deep learning a permis des avancées spectaculaires dans des domaines variés : de la reconnaissance d’images à la traduction automatique, en passant par les assistants vocaux comme Siri et Alexa. Toutefois, cette puissance a un coût : l’entraînement des modèles de deep learning nécessite une énorme capacité de calcul, souvent fournie par des unités de traitement graphique (GPU). Pour en savoir plus sur ce sujet, je vous recommande la lecture de cet article sur l’entrainement des modèles.
Partie 2 : Méthodes d’Apprentissage dans l’IA
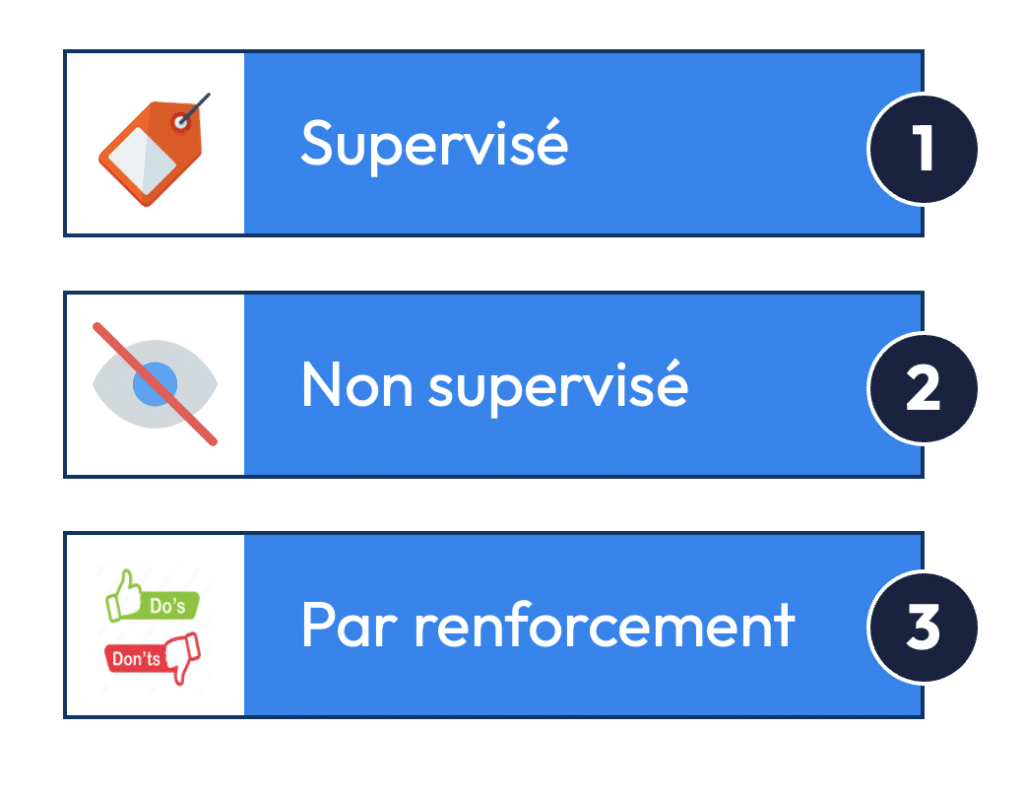
Il existe trois types d’apprentissage en Machine Learning :
2.1 Introduction à l’Apprentissage Supervisé
Le premier type d’apprentissage que l’on rencontre dans le domaine du machine learning est l’apprentissage supervisé. Ce modèle repose sur des données étiquetées, c’est-à-dire des données pour lesquelles on connaît déjà la réponse. Par exemple, si l’on souhaite créer un modèle capable de reconnaître des images de chiens et de chats, on fournira à l’algorithme des milliers de photos, chacune avec une étiquette indiquant si elle représente un chien ou un chat.

Voici le processus de base de l’apprentissage supervisé :
- Étape 1 : Entraînement. L’algorithme reçoit un jeu de données d’entraînement étiquetées (ex. : des images de chiens et de chats) et apprend à identifier les caractéristiques distinctives de chaque classe (chien ou chat).
- Étape 2 : Prédiction. Une fois entraîné, l’algorithme peut prédire à quelle classe appartient une nouvelle image non étiquetée.
- Étape 3 : Validation et ajustement. Si l’algorithme se trompe (par exemple, il prédit qu’une image de chien est un chat), il ajuste ses paramètres internes pour améliorer ses prédictions futures.
–
L’apprentissage supervisé est largement utilisé dans des domaines variés, tels que la classification des spams dans les e-mails, la prédiction du prix de l’immobilier, ou encore la détection de maladies à partir d’images médicales (comme la reconnaissance de fractures sur des radiographies).
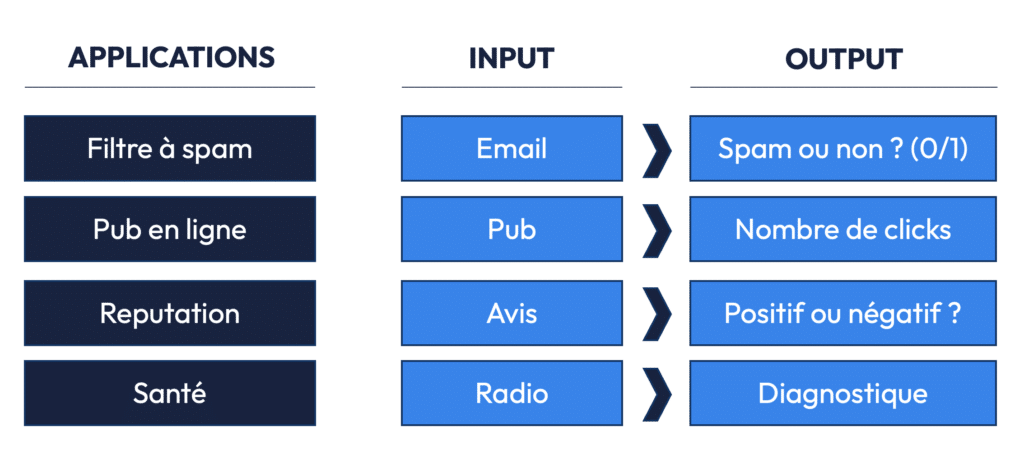
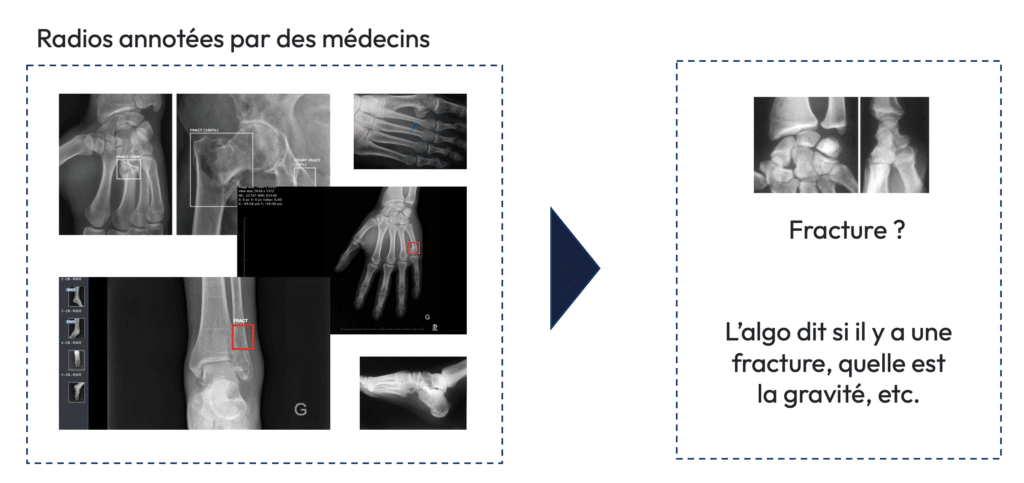
Pour un modèle capable de diagnostiquer des fractures à partir de radiographies, les radiologues fournissent des milliers d’images étiquetées (fracture présente ou non). L’algorithme apprend à reconnaître les patterns associés à une fracture et peut ensuite être utilisé pour assister les médecins dans leurs diagnostics.
Cependant, l’apprentissage supervisé a des limites : il nécessite de grandes quantités de données étiquetées, ce qui peut être coûteux et long à collecter, notamment dans le domaine médical. Le concept d’active learning peut ici être évoqué : il permet à l’IA de demander des données étiquetées sur des aspects spécifiques pour lesquels il manque de connaissances !!
2.2 L’Apprentissage Non Supervisé
Contrairement à l’apprentissage supervisé, l’apprentissage non supervisé ne repose pas sur des données étiquetées. Dans ce modèle, l’algorithme doit découvrir des structures cachées dans les données par lui-même. Ce type d’apprentissage est particulièrement utile lorsqu’il est impossible ou trop coûteux d’étiqueter les données.
Le principal objectif de l’apprentissage non supervisé est de trouver des groupements ou des clusters dans les données. Par exemple, si l’on soumet à un algorithme non supervisé des milliers d’images d’animaux sans préciser leur espèce, il pourra regrouper les images selon des caractéristiques communes, comme la forme ou la couleur, et découvrir ainsi qu’il existe plusieurs types d’animaux dans le jeu de données, même sans savoir ce qu’est un chat ou un chien.
Voici quelques exemples d’applications concrètes de l’apprentissage non supervisé :
- Détection d’anomalies : L’apprentissage non supervisé est utilisé pour identifier des comportements anormaux dans des données financières, détecter des fraudes, ou encore surveiller des infrastructures industrielles.
- Clustering d’avis clients : chez Partoo, la startup dont je suis le co-CEO, nous pouvons utiliser l’apprentissage non supervisé pour analyser des milliers d’avis laissés sur des points de vente. L’IA peut regrouper les avis autour de thématiques récurrentes (ex. : avis sur la rapidité du service, sur la qualité des produits, etc.), sans qu’il soit nécessaire de spécifier au préalable ces thèmes.
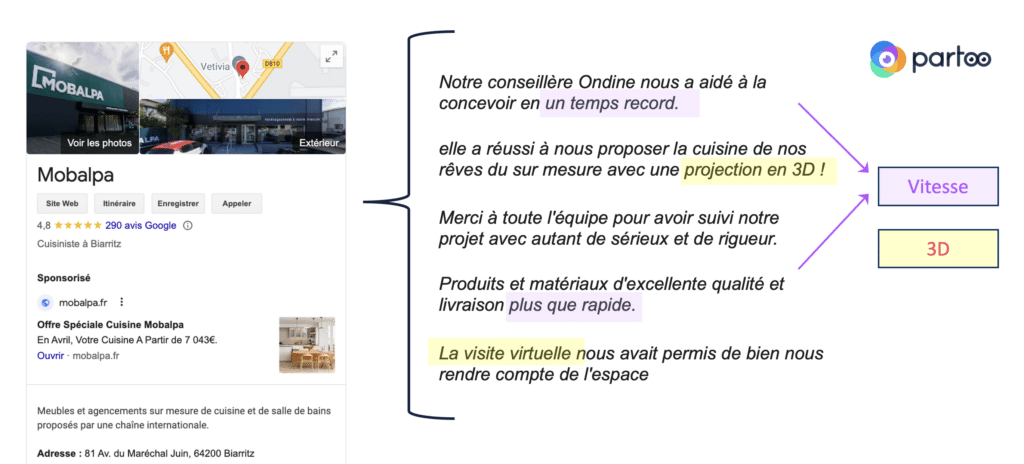
Une fois les thèmes identifiés dans les avis clients, nous pouvons savoir si ces thèmes sont des forces ou des faiblesses de l’enseigne (Castorama, Leroy Merlin…) et établir un plan d’action !
–

L’un des principaux algorithmes d’apprentissage non supervisé est le k-means clustering, qui permet de partitionner les données en k groupes. Un autre exemple est l’algorithme de réduction de dimensionnalité t-SNE, qui aide à visualiser des données complexes en deux ou trois dimensions.
2.3 L’Apprentissage par Renforcement
L’apprentissage par renforcement est un modèle où l’algorithme apprend à partir des conséquences de ses actions, en recevant des récompenses ou des punitions en fonction de la qualité de ses décisions. Ce modèle est largement inspiré de la façon dont les humains apprennent par essais et erreurs.
Dans l’apprentissage par renforcement, l’algorithme, souvent appelé agent, interagit avec un environnement et prend des décisions à chaque étape. Si la décision de l’agent mène à un résultat positif, il reçoit une récompense. Sinon, il est pénalisé. L’objectif de l’agent est de maximiser la somme des récompenses au fil du temps.
L’apprentissage par renforcement est utilisé dans des domaines variés comme :
- Les jeux vidéo et l’apprentissage automatique des robots. Par exemple, AlphaGo, développé par DeepMind (filiale de Google), utilise l’apprentissage par renforcement pour apprendre à jouer au jeu de Go. Il a battu le champion du monde en 2016, marquant une nouvelle étape dans les capacités des IA à surpasser l’humain dans des tâches complexes.
- La conduite autonome. Les voitures autonomes utilisent des algorithmes d’apprentissage par renforcement pour prendre des décisions de conduite en temps réel, en fonction de l’environnement et des règles de circulation.
L’apprentissage par renforcement est particulièrement adapté aux environnements dynamiques et incertains, où les algorithmes doivent constamment ajuster leurs décisions en fonction des retours qu’ils reçoivent.
Dans des LLM comme ChatGPT, un exemple concret d’apprentissage par renforcement est le Renforcement Learning with Human Feedback (RLHF) – sujet que j’aborde dans le 3ème webinar de cette série à retrouver en suivant ce lien. Cette méthode est utilisée pour ajuster les réponses des modèles en fonction des préférences humaines, garantissant ainsi que l’IA produit des réponses conformes aux attentes éthiques et sociales.
Passions maintenant au Deep Learning qui est une forme de Machine Learning :
2.4 Le Deep Learning et l’Apprentissage via des Réseaux Neuronaux
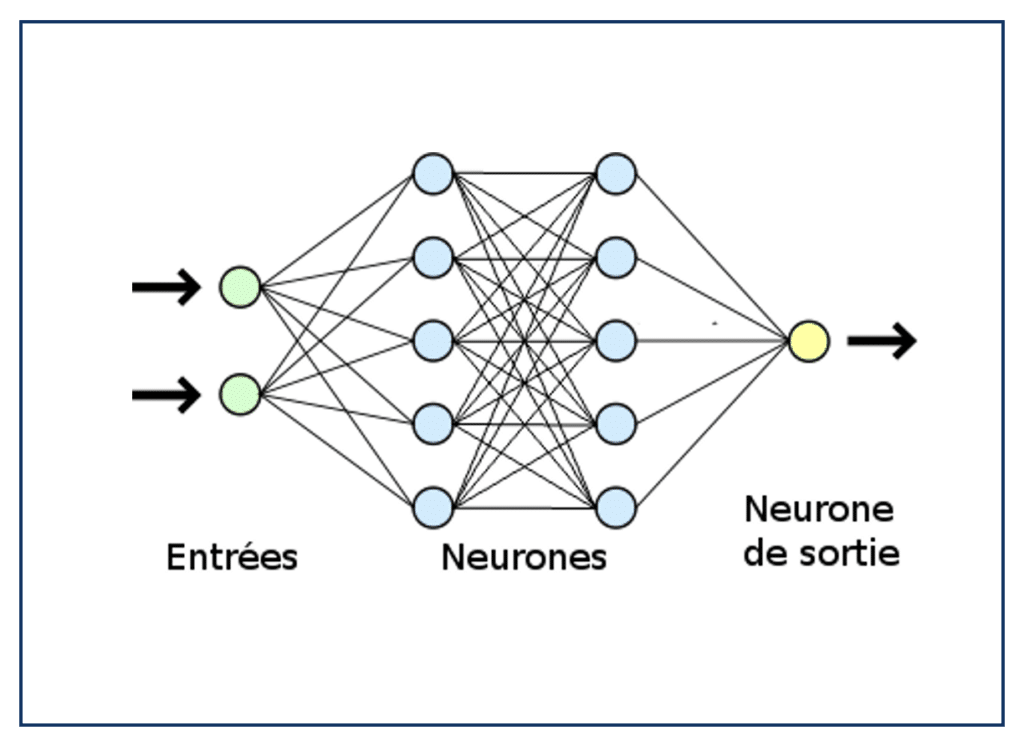
Le Deep Learning, ou apprentissage profond, est une approche qui exploite des réseaux de neurones artificiels pour traiter de grandes quantités de données non structurées. Les réseaux de neurones sont inspirés de la structure du cerveau humain, où des neurones sont interconnectés pour former des couches profondes capables d’apprendre des représentations complexes des données.
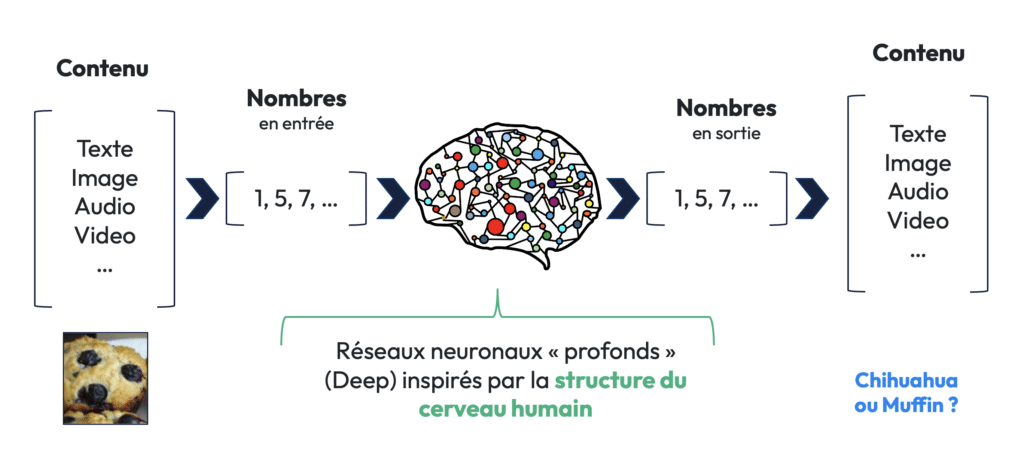
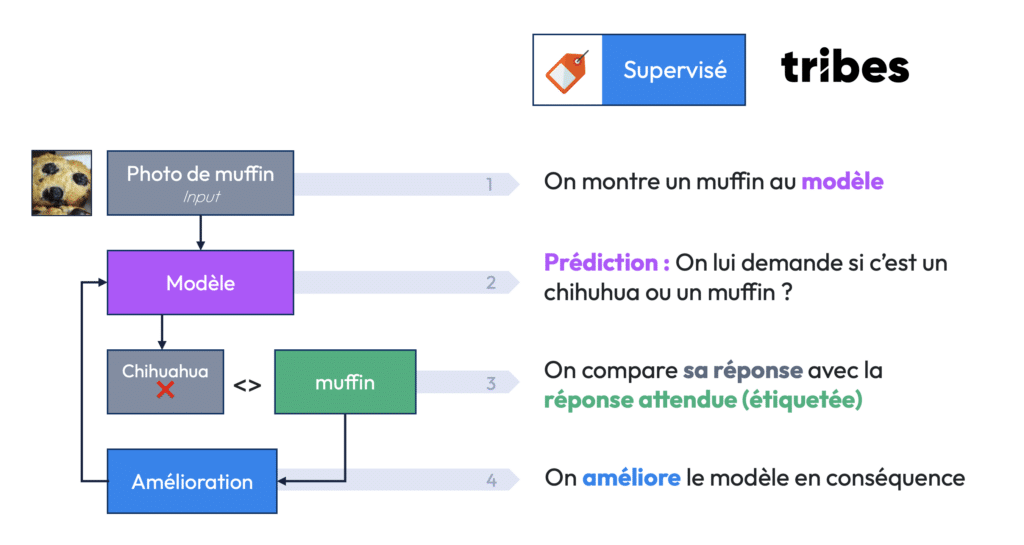
Voici un exemple concret pour illustrer le deep learning : imaginons que l’on souhaite entraîner un modèle pour différencier des images de muffins et de chihuahuas. Dans l’apprentissage classique, on fournirait des règles explicites à l’algorithme (ex. : les chiens ont des oreilles, les muffins non). Mais avec le deep learning, au lieu de fournir ces règles, on montre simplement à l’algorithme des milliers d’exemples, et il apprend à reconnaître les patterns par lui-même.
Le processus d’apprentissage dans un réseau de neurones passe par les étapes suivantes :
- Entrée des données (input). L’image est traduite en une série de nombres qui représentent les pixels.
- Passage à travers plusieurs couches de neurones. Chaque couche apprend à détecter des patterns de plus en plus complexes (ex. : des lignes, puis des formes, puis des objets entiers).
- Sortie des données (output). Le réseau fait une prédiction (muffin ou chihuahua).
Le deep learning est une technologie clé derrière des applications comme la reconnaissance faciale, la traduction automatique et la vision par ordinateur. Yan LeCun, lauréat du prix Turing en 2018, est l’un des pionniers dans le développement de cette technologie.
–
Partie 3 : Les Différentes Applications de l’IA et ses Domaines
–
3.1 Le Traitement du Langage Naturel (NLP)
Le traitement du langage naturel (NLP) est l’un des domaines les plus dynamiques de l’intelligence artificielle aujourd’hui. Le NLP vise à permettre aux machines de comprendre, générer et interagir avec du texte ou de la parole humaine.
Les modèles de langage de grande taille (LLM), comme GPT-3 et BERT, sont des exemples emblématiques de la puissance du NLP. Ils sont capables de comprendre le contexte de mots dans une phrase, de traduire des textes, de résumer des documents, ou encore d’analyser des sentiments à partir de critiques en ligne.
Les applications concrètes du NLP sont nombreuses :
- Chatbots et assistants vocaux. Des assistants comme Siri, Alexa, ou les chatbots des services clients utilisent des modèles NLP pour comprendre et répondre aux questions des utilisateurs en langage naturel. Chez Partoo nous avons développé notre propre chatbot (JIM), utilisé sur les sites des enseignes comme Glassdrive ou Cashconverter belgique : il est capable de répondre à tout type de questions en s’appuyant sur une base de connaissance fournie par l’entreprise ! Si vous souhaitez en savoir plus sur le sujet des chatbots, des agents et des Agentic System, n’hésitez pas à vous référer à cet article ou au 4ème webinar de cette série.
- Traduction automatique. Des services comme Google Translate utilisent des modèles NLP pour traduire des textes d’une langue à une autre avec un haut degré de précision.
- Analyse de sentiment : Partoo utilise le NLP pour analyser des avis clients et déterminer sur quoi ils portent et si les commentaires sont positifs ou négatifs.
Le NLP et les LLM sont au cœur du deuxième webinar de cette formation, où les concepts de tokenisation, vectorisation et modèle Transformers sont notamment abordés plus en profondeur.
3.2 La Vision par Ordinateur (Computer Vision)
La vision par ordinateur (computer vision) est un autre domaine clé de l’intelligence artificielle. Elle permet aux machines de comprendre, interpréter et même générer des images et des vidéos.
Voici quelques-unes des principales applications de la vision par ordinateur :
- Reconnaissance d’images. Les algorithmes peuvent reconnaître des objets dans des images ou des vidéos (ex. : identifier des voitures dans une vidéo de circulation).
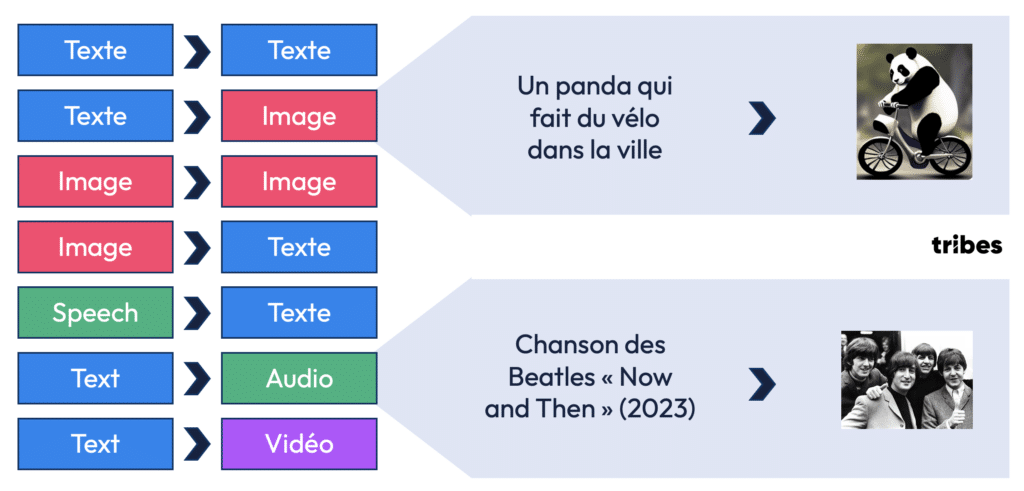
- Génération d’images. Des modèles comme DALL·E ou Stable Diffusion permettent de créer des images à partir d’instructions textuelles. Par exemple, l’utilisateur peut demander une image d’un « panda sur un vélo dans une ville » et l’IA générera une image réaliste correspondant à cette description.

Au delà de se faire par entrainement supervisé (on fournit des images de pastèques pour demander à l’IA dans générer une nouvelle), la génération d’image se fait par “Diffusion model” – si vous souhaitez creuser les différents sujets de cet article, n’hésitez pas à vous référer au webinar, un peu plus complet que cette retranscription.
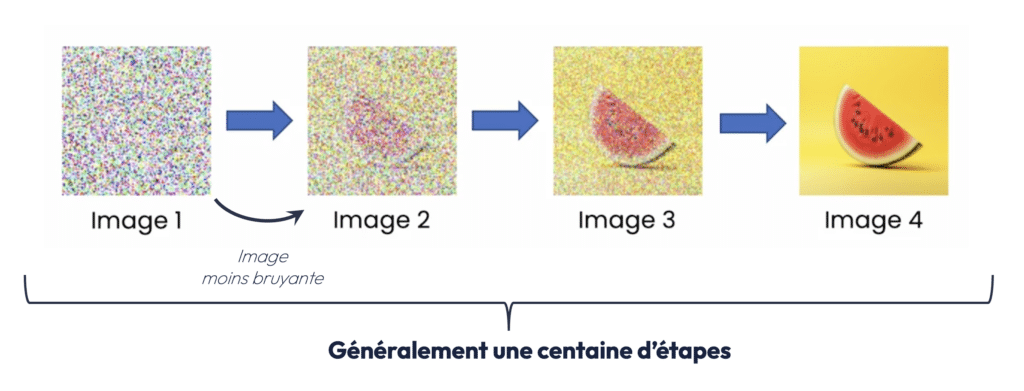
Un concept important dans la vision par ordinateur est celui des réseaux de neurones convolutifs (CNN). Les CNN sont des algorithmes spécialement conçus pour traiter les images. Ils fonctionnent en divisant l’image en de petites régions appelées “filtres”, qui détectent des patterns visuels comme les lignes, les formes et les textures.
A ce sujet je vous conseille notamment une série de formations proposées par IBM que j’ai adorée – en particulier vous pouvez regarder la vidéo spécifique sur les CNN.
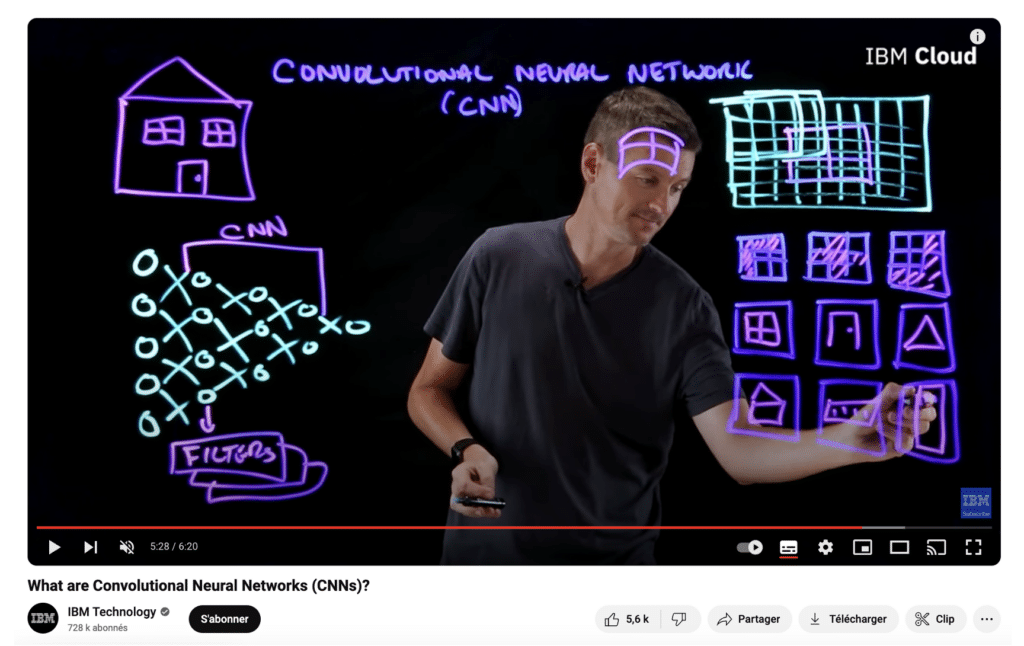
3.3 Les GAN et la Génération d’Images
Les réseaux génératifs adversaires (GAN) sont une innovation clé dans le domaine de la génération d’images. Ils reposent sur l’interaction de deux modèles distincts : un générateur et un discriminateur. Le générateur crée des images à partir de bruit aléatoire (Diffusion Model), tandis que le discriminateur tente de déterminer si ces images sont réelles ou générées.
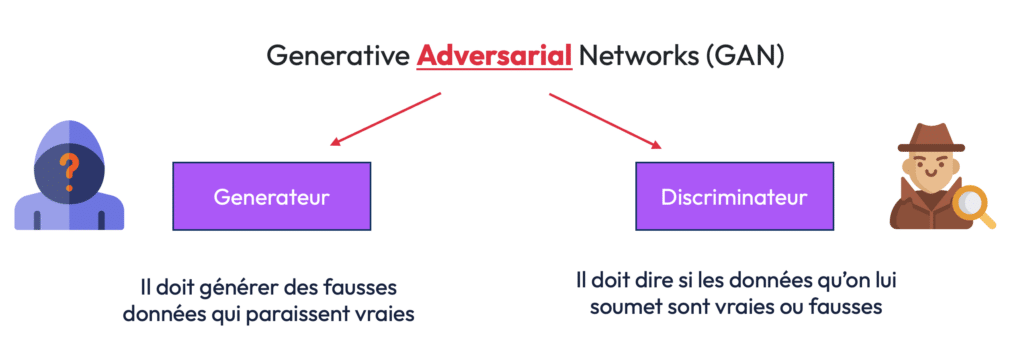
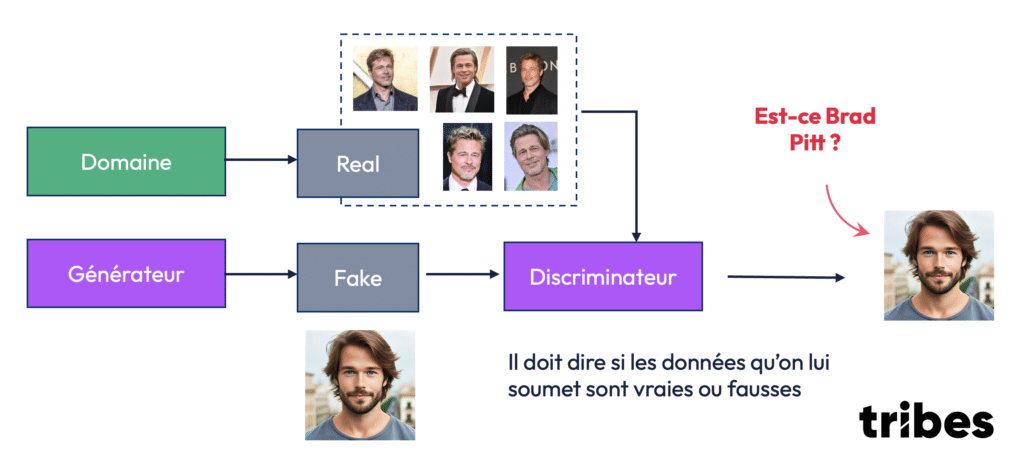
Le processus fonctionne ainsi :
- Le générateur produit une image artificielle – ex. qui doit ressembler à Brad Pitt !
- Le discriminateur reçoit cette image ainsi que des images réelles, et doit déterminer si l’image est vraie ou fausse.
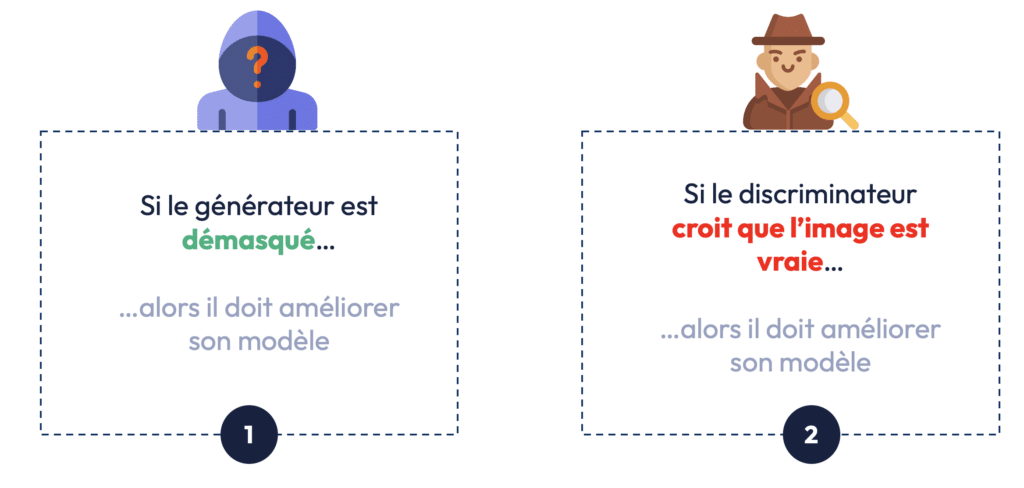
- Si le discriminateur identifie l’image comme fausse, le générateur ajuste ses paramètres pour tromper le discriminateur lors de la prochaine tentative.
Ce modèle en “duel” permet d’améliorer progressivement la qualité des images générées, jusqu’à créer des images si réalistes qu’il devient difficile, même pour un humain, de les distinguer des vraies.
Les deepfakes, des vidéos ou images manipulées pour faire croire que des personnes disent ou font des choses qu’elles n’ont jamais faites, sont des exemples frappants de ce que les GAN peuvent accomplir.

Bien que les deepfakes posent de sérieux enjeux éthiques et politiques, les GAN ont aussi des applications positives, comme la dépixélisation d’images par exemple. Dans certains cas, les GAN sont utilisés pour recréer des images en haute résolution à partir de versions pixélisées ou floues, comme c’est le cas dans la restauration de vidéos anciennes.
3.4 La Robotique et l’IA dans l’Industrie
Bien que ce sujet n’ait pas été couvert en profondeur dans cette première session, la robotique est un autre domaine où l’intelligence artificielle joue un rôle crucial. Les robots industriels, les drones autonomes, et même les robots humanoïdes comme ceux développés par Boston Dynamics sont des exemples de systèmes où l’IA et le machine learning permettent aux machines d’interagir physiquement avec le monde qui les entoure.
Les applications de l’IA en robotique sont variées :
- Automatisation des processus industriels. Dans les usines, des robots assistés par IA sont utilisés pour des tâches de production répétitives, mais aussi pour des tâches complexes comme la détection de défauts dans les produits ou la gestion des stocks.
- Conduite autonome. Des entreprises comme Tesla utilisent l’IA pour développer des voitures capables de conduire de manière autonome.
–
Partie 4 : Les Capacités de l’IA et son Futur
4.1 L’IA Générative : Analyse et Création
L’une des distinctions fondamentales à comprendre est celle entre l’IA analytique et l’IA générative. Alors que le machine learning classique se concentre sur l’analyse des données (ex. : reconnaissance d’images, prévisions financières…), l’IA générative est capable de créer du contenu original, que ce soit du texte, des images ou même de la musique.
–

Voici quelques exemples d’applications d’IA générative :
- Création de contenu artistique. Des algorithmes comme DALL·E ou MidJourney permettent de générer des œuvres d’art en fonction d’instructions textuelles.
- Musique générée par IA. En 2023, une chanson des Beatles intitulée Now and Then a été créée en partie à l’aide de l’intelligence artificielle, bien que le groupe ait cessé d’enregistrer depuis des décennies.
L’IA générative représente une révolution pour de nombreux secteurs, qu’il s’agisse de la création artistique, du marketing ou même de la recherche scientifique. Toutefois, elle soulève également des questions éthiques et juridiques, notamment en ce qui concerne les droits d’auteur et les risques d’abus (ex. : deepfakes).
4.2 De l’IA Étroite à l’IA Générale
La plupart des applications actuelles de l’IA relèvent de ce que l’on appelle l’IA étroite (ou spécialisée). Ces IA sont conçues pour accomplir des tâches spécifiques, comme jouer aux échecs ou traduire un texte. Elles excellent dans leur domaine, mais sont incapables de s’adapter à d’autres tâches sans être reprogrammées
En revanche, l’objectif ultime de la recherche en IA est de développer une intelligence artificielle générale (AGI), une IA capable d’apprendre et de comprendre n’importe quelle tâche, à un niveau équivalent, voire supérieur, à celui d’un humain.
Les modèles multimodaux, capables de traiter à la fois des images, du texte, des vidéos et des sons, représentent un pas vers cette AGI. Des systèmes comme ChatGPT-4 intègrent déjà plusieurs modalités (texte, image) pour offrir des interactions plus riches.
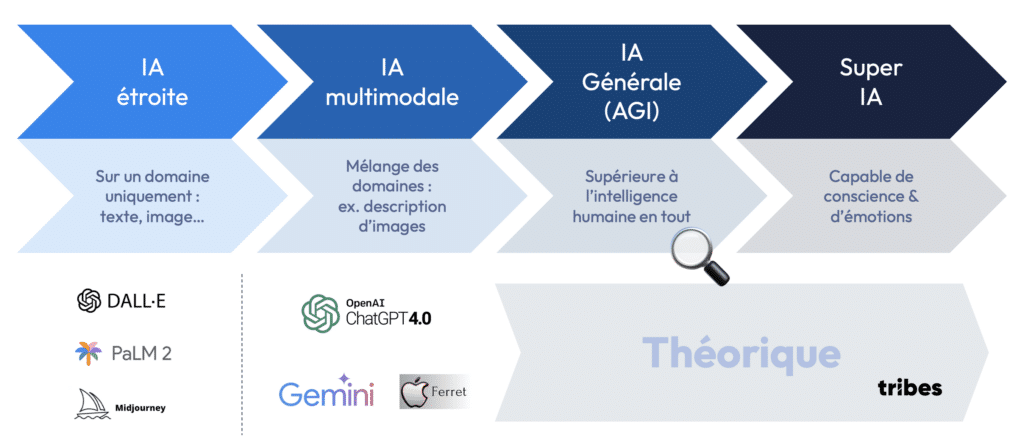
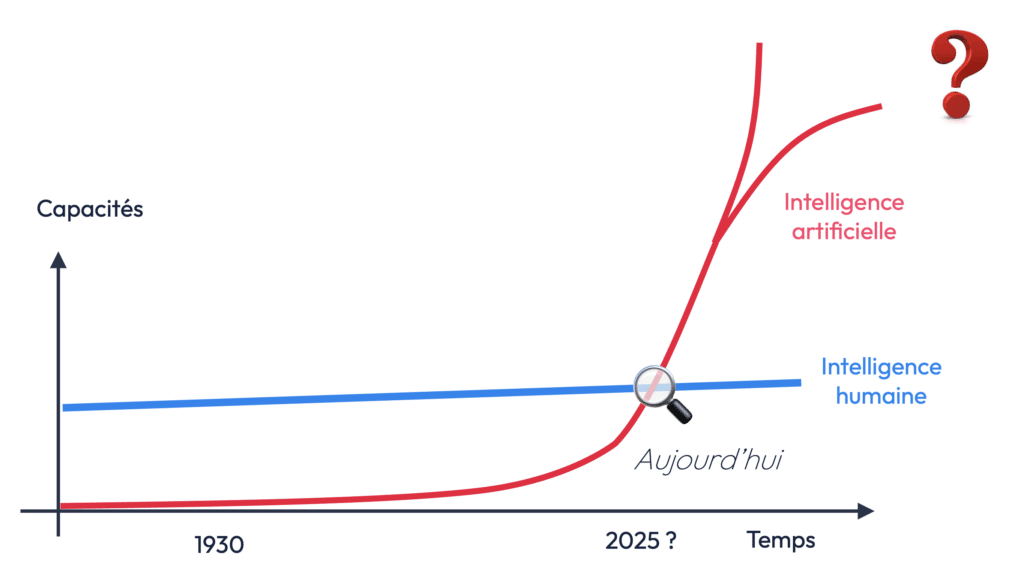
Enfin, au-delà de l’AGI, certains chercheurs spéculent sur l’émergence d’une superintelligence artificielle, un système capable de conscience et d’émotion, surpassant l’intelligence humaine. Bien que cela reste pour l’instant de la science-fiction, des progrès rapides en IA laissent entrevoir des développements fascinants dans les années à venir.
–
Conclusion et Perspectives
Ce premier webinar – retranscrit en partie en article ici – pose quelques bases de la compréhension de l’IA, du machine learning et du deep learning.
Les sessions futures se concentreront sur des sujets plus spécifiques, notamment :
- Le traitement du langage naturel (NLP) et les modèles de langage de grande taille (LLM) (webinar 2 à consulter ici)
- Les méthodes d’entraînement des modèles d’IA, avec un focus sur les concepts de fine-tuning, de reinforcement learning et d’optimisation des modèles.
- L’impact de l’IA dans les domaines du cloud computing, de la robotique, et des agents virtuels.
Les implications de ces technologies pour les entreprises, les gouvernements, et les individus sont énormes, et il est essentiel de se former pour mieux comprendre les défis et les opportunités qu’elles présentent – c’est ce que nous faisons à la fois chez Tribes & chez Partoo !
En résumé, l’IA n’est pas seulement une technologie d’avenir : elle façonne déjà le présent, et ceux qui sauront l’utiliser efficacement seront en mesure de transformer leurs secteurs d’activité et de contribuer à une nouvelle ère de l’innovation.