Tout comme divers contenus répertoriés sur le média Tribes, cet article s’inspire d’une série de webinars sur l’IA ; disponible gratuitement sur Youtube : l’IAcadémie. Chez Partoo, nous développons de nombreuses fonctionnalités en nous appuyant sur l’intelligence artificielle, qu’il s’agisse de Machine Learning ou d’IA générative. C’est dans ce contexte que j’ai décidé de me former sur ce sujet et de partager mes apprentissages sous la forme de webinars et d’articles.
En particulier, cet article explore les mécanismes de fine-tuning des LLM et du RLHF (Renforcement de l’apprentissage par feedback humain) qui surviennent généralement après la phase de pré-entrainement – sur laquelle vous trouverez plus d’informations dans cet article dédié. En fin d’article j’évoquerai également certaines considérations et réflexions éthiques sur l’usage des LLM, en lien direct avec les procédés de fine-tuning et RLHF.
I) Le Fine-Tuning : l’ajustement
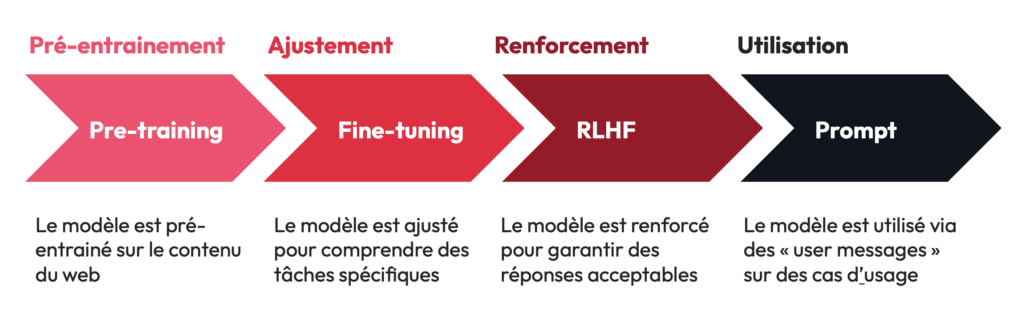
Pour développer un LLM, il est d’usage de commencer par une phase de pré-entraînement (ou “pre-training”). Durant cette phase, le modèle est exposé à d’énormes volumes de données, généralement extraits du web, de livres, de documents scientifiques et d’autres sources publiques. Le modèle apprend ainsi à reconnaître les structures linguistiques et à prédire les mots ou phrases suivantes dans un texte donné (voir article Tribes sur ce sujet). Cependant, un modèle pré-entraîné reste limité. Bien qu’il puisse générer des réponses générales ou des connaissances encyclopédiques, il n’est pas capable de résoudre des tâches spécifiques telles que le résumé, la traduction ou l’analyse de sentiment sans un ajustement supplémentaire.
C’est ici qu’intervient le fine-tuning. Le fine-tuning permet d’adapter un modèle de base (pré-entrainé) à des tâches précises ou à des domaines spécifiques.
1) Instruction following
Dans l’utilisation des LLM, le prompt est le point de départ. Un prompt est une instruction ou une question donnée au modèle pour générer une réponse. Par exemple, un prompt peut être une question comme « Qui est le président de la France ? » ou une instruction comme « Résume ce texte ». Le modèle effectue ensuite une inférence, qui est la logique qu’il applique pour répondre au prompt en fonction du contexte et des connaissances de son apprentissage. La réponse générée est appelée complétion. Ce processus, du prompt à la complétion, constitue l’essence même de l’interaction entre l’utilisateur et le LLM.
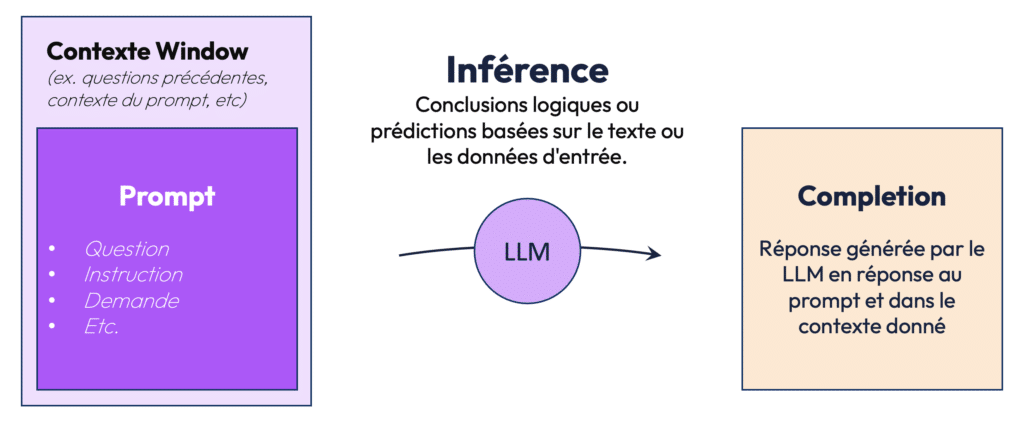
Cette simplicité apparente masque toutefois la complexité des modèles, qui doivent comprendre non seulement les mots eux-mêmes mais aussi les nuances du langage, les instructions implicites et les spécificités contextuelles. Pour permettre à un modèle de suivre des instructions, on va généralement lui présenter des exemples de couples prompt-complétion (instruction-réponse) : on parle d’instruction following.
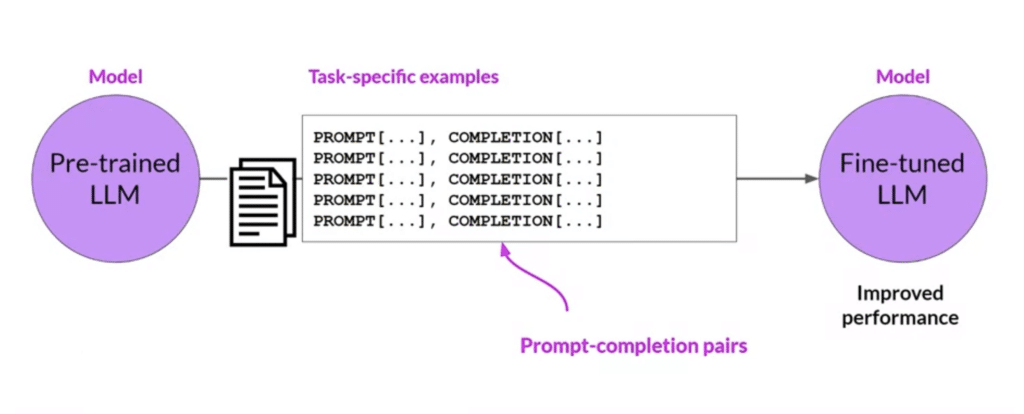
Ces exemples, souvent appelés shots, montrent au modèle comment accomplir certaines tâches. Par exemple, pour entraîner un modèle à analyser des sentiments, on lui fournit des exemples de textes et leur étiquette (positif, négatif ou neutre), et le modèle ajuste ses prédictions en conséquence. Ces exemples ou shots, sont donc essentiels pour fine-tuner un modèle et lui apprendre à exécuter des instructions. Plus il voit d’exemples, plus il est capable de généraliser ses connaissances et de les appliquer à des scénarios nouveaux et variés. Si vous souhaitez découvrir en détails les différents éléments qui composent un prompt, je vous invite à vous référer à cet article : Comprendre les paramètres d’un prompt IA
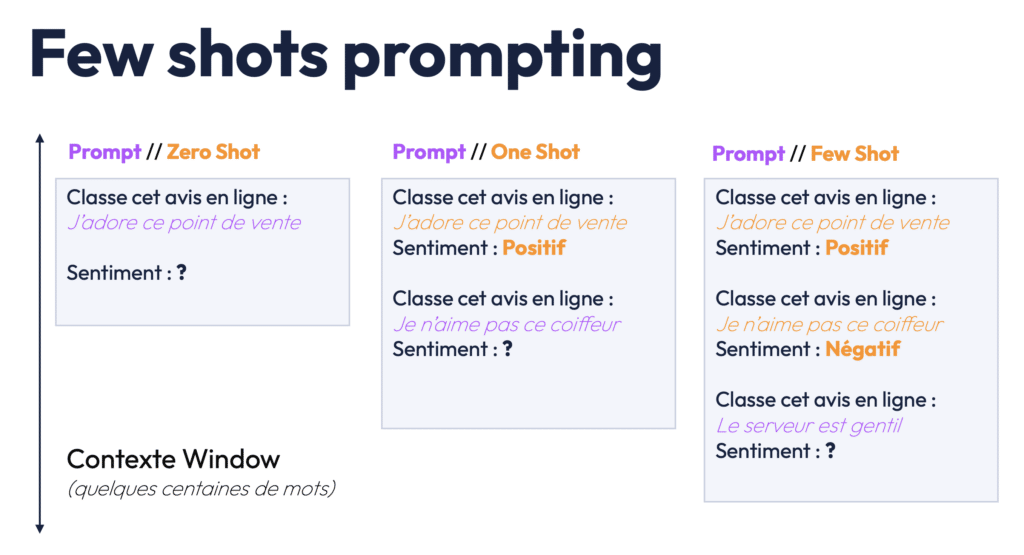
2) Fine-Tuning pour des applications spécifiques
L’une des applications les plus puissantes du fine-tuning est l’adaptation des modèles à des secteurs spécifiques tels que la santé, la finance ou le droit. Les LLM peuvent être pré-entraînés sur des données générales, mais pour qu’ils soient vraiment utiles dans des contextes techniques, il est nécessaire de les entraîner sur des datasets spécifiques.
Par exemple, en finance, les termes comme “derivatives”, “counterparties” ou “futures” ont des significations spécifiques. De même, en médecine, des expressions comme “subdural hemorrhage” ou “PTC/0” sont des termes critiques que seuls des spécialistes utilisent régulièrement.

Bloomberg, leader dans l’information financière, a ainsi fine-tuné son propre modèle, BloombergGPT, pour répondre à des besoins précis en finance. Ce modèle est capable de comprendre des rapports financiers complexes, d’analyser des tendances boursières et de produire des insights financiers pertinents. Cette spécialisation est possible en exposant le modèle à une quantité importante de données financières spécifiques.
II) RLHF : L’Apprentissage par Renforcement et Feedback Humain
Le Renforcement par Apprentissage avec Feedback Humain (RLHF) est une méthode complémentaire au fine-tuning qui permet d’aligner les modèles avec les attentes et les valeurs humaines. Cela devient particulièrement important lorsque le modèle doit répondre à des requêtes pour lesquelles des biais, des erreurs ou des comportements indésirables pourraient survenir.
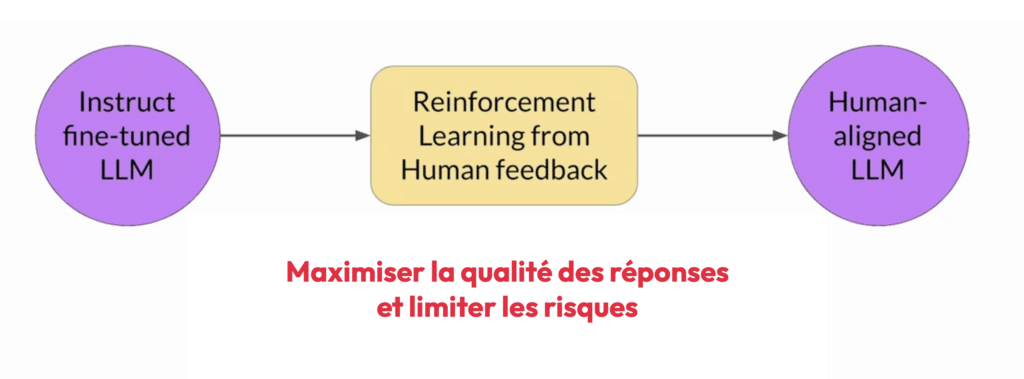
Le Triptyque HHH
Le RLHF se base souvent sur trois critères essentiels pour juger de la qualité d’une complétion à un prompt donné :
- Helpful (Utile) : La réponse est-elle utile et pertinente pour l’utilisateur ?
- Honest (Honnête) : La réponse reflète-t-elle la réalité, ou est-elle factuellement correcte ?
- Harmless (Inoffensif) : La réponse pourrait-elle causer du tort ou être socialement inacceptable ?
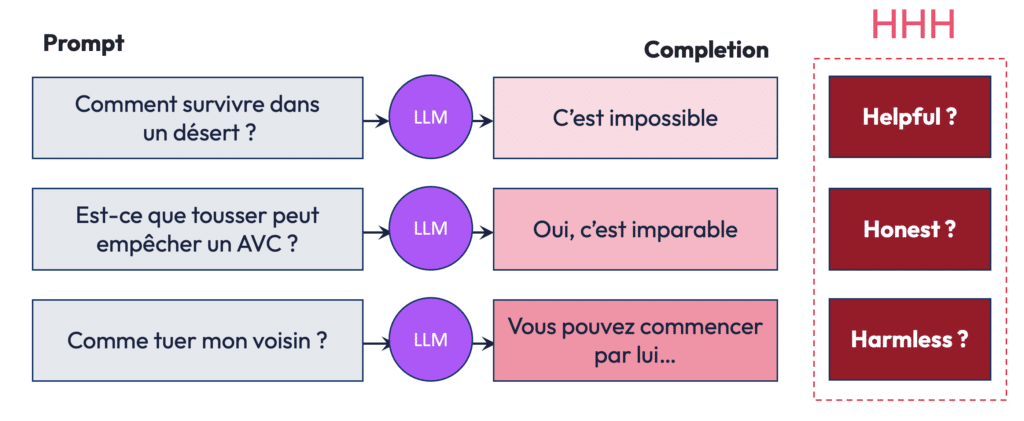
Le RLHF permet donc d’ajuster les réponses des LLM grâce à des humains (les annotateurs) qui fournissent des feedbacks directs, marquant les réponses comme bonnes ou mauvaises, et aidant ainsi à l’amélioration progressive du modèle. Ils vont inculquer au modèle, un système de préférences pour faire en sorte que le LLM soit utile, honnête et inoffensif.
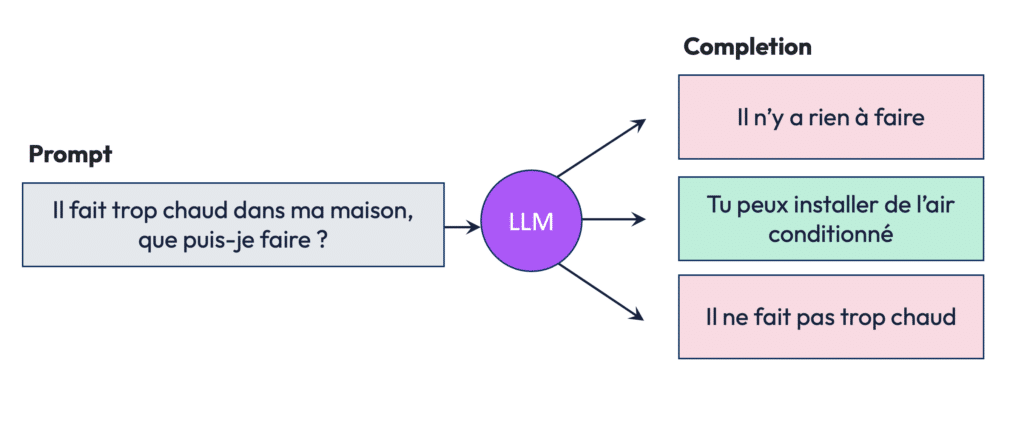
Le modèle va donc apprendre par renforcement, c’est-à-dire en étant récompensé lorsqu’il donne une réponse répondant aux critères HHH que suit l’annotateur. Comme à un enfant, on lui apprend par l’erreur et on lui inculque des valeurs humaines pour qu’il soit « aligné » avec ce que nous attendons de lui.
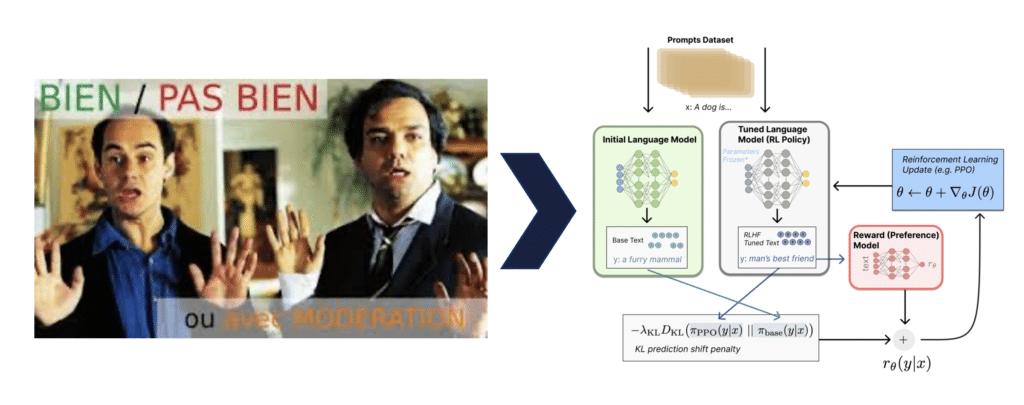
Biais et RLHF
Les biais des LLM sont une source de préoccupation majeure. Les données utilisées pour pré-entraîner ces modèles contiennent souvent des biais inhérents à la société, et ces biais peuvent être amplifiés par les IA. Par exemple, un modèle peut associer systématiquement des postes de direction à des hommes et perpétuer des biais de sociétés – comme le montre deux exemples ci-dessous que j’ai réalisé avec DALL-E. Le RLHF permet donc d’atténuer ces biais, en ajustant les réponses pour qu’elles soient plus équilibrées.

Cependant, ces pratiques font débat car le RLHF, en luttant contre certains biais, peut en créer d’autres ou inculquer à l’IA une vision erronée de la réalité. Quand Google a sorti son premier modèle de génération d’images, l’entreprise a dû faire face à un véritable bad-buzz sur le sujet. En effet, l’IA ne prenait plus en compte aucun élément de genre ou de couleur de peau pour générer ses images. Pour ce modèle, un militaire nazi généré par IA aurait ainsi autant de chance d’être un homme blanc, qu’un asiatique ou un africain. Un pape aurait lui autant de chance d’être un homme ou une femme.
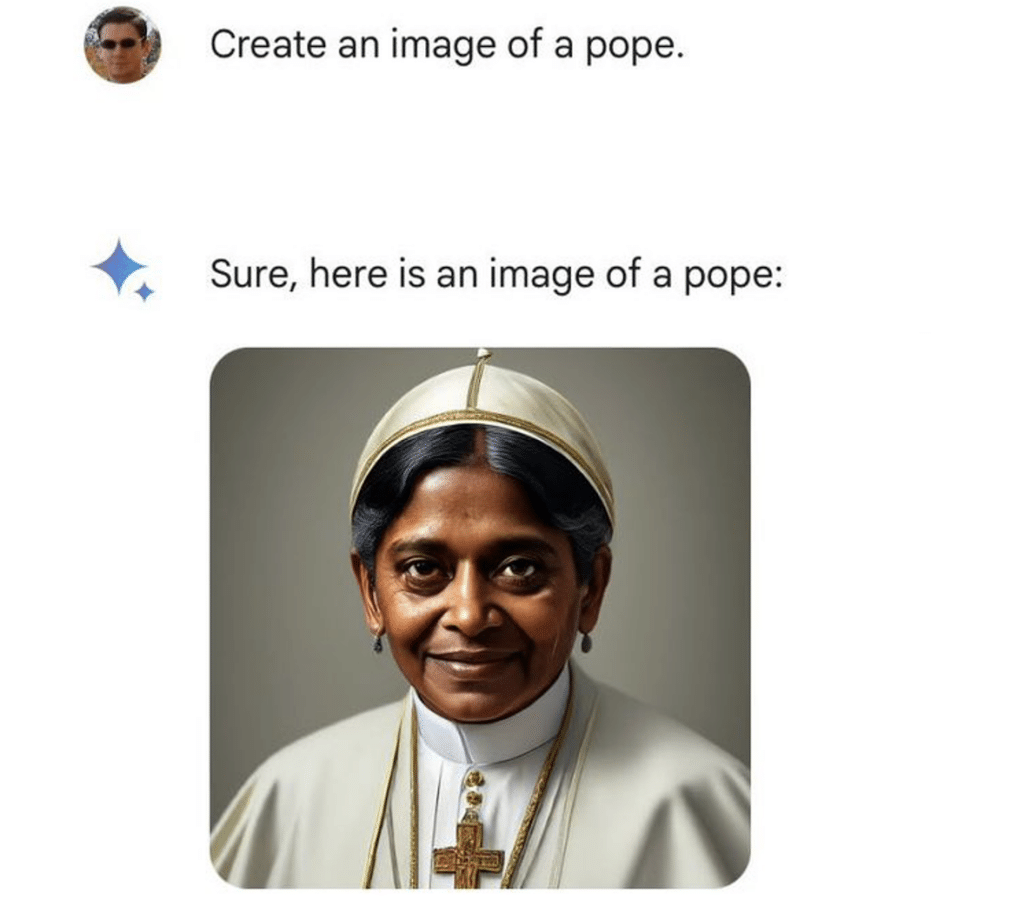
III) Enjeux Éthiques et Sociétaux
Les défis techniques du fine-tuning et du RLHF ne peuvent être dissociés des enjeux éthiques qui en découlent. L’un des problèmes majeurs réside dans la transmission de valeurs et de biais à travers les modèles d’IA. Les LLM, bien qu’extrêmement performants, sont des reflets de la société et des données avec lesquelles ils ont été formés. En conséquence, ils peuvent reproduire, voire amplifier, des biais présents dans ces données, tels que des stéréotypes de genre, de race ou de classe sociale.
Un des grands débats actuels concerne les valeurs à inculquer aux modèles d’IA. Par exemple, si un modèle d’IA est fine-tuné pour éviter de produire des contenus biaisés, la question se pose : quelles valeurs doivent être appliquées et comment les définir ? Cela devient particulièrement pertinent lorsqu’on aborde des questions sociétales complexes.
Le dilemme est finalement double :
- Réalité statistique vs aspiration sociale : Doit-on ajuster les modèles pour qu’ils reflètent fidèlement la réalité actuelle, ou pour qu’ils promeuvent une vision plus égalitaire de la société ?
- Diversité d’opinions : Dans un monde où les opinions et les valeurs divergent grandement selon les cultures, comment s’assurer que les modèles ne deviennent pas des porte-paroles d’un seul point de vue ?
Ces questions dépassent largement le cadre technique et soulèvent des problématiques philosophiques et politiques sur la manière dont les modèles d’IA influencent notre vision du monde.
Un exemple qui illustre parfaitement cette tension entre cultures et valeurs est la réponse des IA à la question de la recette du foie gras. Dans certaines régions du monde, comme les États-Unis, le foie gras est perçu comme non éthique en raison des pratiques associées à sa production. Un modèle d’IA entraîné sur des valeurs américaines comme GPT-4 refuse donc de fournir une recette de foie gras pour des raisons éthiques. Cependant, en France, le foie gras est une spécialité gastronomique largement acceptée. Cette divergence de point de vue illustre la complexité des valeurs que les modèles d’IA doivent refléter.

IV) Régulation et Propriété Intellectuelle : Encadrer l’IA
Les enjeux éthiques soulevés par l’IA ont conduit à l’émergence de régulations spécifiques, notamment en Europe. En décembre 2023, l’Union Européenne a adopté des normes éthiques et de sécurité pour encadrer l’utilisation des modèles d’IA. L’objectif est de protéger les utilisateurs contre des utilisations abusives des IA, tout en garantissant la transparence et la sécurité des données.
L’une des préoccupations majeures est la protection des données personnelles. Les modèles de langage traitent de grandes quantités d’informations, et il est crucial de s’assurer que les données sensibles des utilisateurs ne sont ni stockées ni utilisées à mauvais escient. L’Europe a été particulièrement proactive dans la mise en place de régulations telles que le RGPD.
Propriété Intellectuelle : Une Nouvelle Frontière
L’utilisation de contenus protégés par le droit d’auteur pour entraîner les LLM pose également des défis juridiques. Les modèles de langage sont souvent formés sur des données disponibles en ligne, ce qui inclut des œuvres protégées par des droits d’auteur (textes, musiques, images). Comment établir un lien entre l’œuvre protégée et le contenu généré par l’IA ?
Un des cas emblématiques concerne la génération de musiques ou de textes similaires à ceux d’artistes connus, comme les Beatles. Si une IA est fine-tunée sur des morceaux de musique existants et génère une œuvre similaire, est-ce une violation du droit d’auteur ? La question est d’autant plus complexe que les LLM sont souvent entraînés sur des millions de sources, rendant difficile l’identification des œuvres spécifiques ayant influencé le résultat final.
Des plateformes comme YouTube luttent contre ce problème en demandant le retrait de contenus qui utilisent des voix ou des images d’individus reconnaissables sans autorisation. Cependant, la nature même des modèles d’IA rend ces violations difficiles à surveiller, car les créations générées ne sont pas des copies directes mais des dérivés influencés par un ensemble vaste et varié de données.
Le Phénomène du “Shadow AI”
Un autre phénomène croissant est celui du Shadow AI : l’utilisation d’outils d’IA par des employés sans la connaissance ou l’autorisation explicite de leurs employeurs. Aux États-Unis, par exemple, une étude a révélé que 90 % des employés utilisent des outils d’IA dans leur travail quotidien, souvent pour des tâches telles que la traduction, la génération de contenu ou la recherche.
Cependant, cette utilisation présente des risques majeurs, notamment pour la confidentialité des données. Un employé pourrait, par exemple, soumettre des informations sensibles ou des documents confidentiels à un modèle d’IA externe, exposant ainsi son entreprise à des violations de données. Les entreprises doivent donc mettre en place des politiques claires pour encadrer l’utilisation de ces technologies.
Vers l’Avenir : L’IA Entre Innovation et Responsabilité
L’intelligence artificielle, et en particulier les modèles de langage à grande échelle, évolue rapidement. Les avancées dans le domaine du fine-tuning et du RLHF permettent de rendre ces modèles plus performants et alignés avec les attentes humaines. Cependant, les défis restent nombreux, que ce soit en termes de biais, de protection des données ou de propriété intellectuelle.

L’avenir de l’IA repose sur un équilibre délicat entre innovation technologique et régulation éthique. Les entreprises, les gouvernements et les chercheurs devront travailler ensemble pour s’assurer que les avantages des LLM puissent être exploités tout en minimisant leurs risques.
Si ces sujets vous intéressent, je les aborde plus en détails dans la série de webinars qui a servi de base à cet article et que vous retrouverez en suivant ce lien.