Vous l’avez sans doute remarqué, il y a de plus en plus de profils et de départements Data dans les start-up de l’écosystème Tech.
Il est devenu assez rare de voir une start-up (ou scale-up) de plus de 100 personnes sans au moins 1 ou 2 personnes dans le département Data.
Cependant, le rôle de cette équipe est encore souvent mal compris et la Data apparaît encore à certains comme une science mystique – alors que les problématiques autour de la Data sont de plus en plus ancrés dans les métiers opérationnels (Sales, Customer Success, Marketing, Product, Support etc.).

Il est rare de voir des équipes métiers travailler efficacement avec les équipes Data en start-up.
Bien souvent, les échanges se limitent à des demandes ponctuelles et tactiques (comme des demandes de requêtes SQL) ; au lieu de collaborer sur des sujets plus profonds et créateurs de valeur.
Les métiers de la data
Par ailleurs, les métiers de la Data vont continuer leur développement exponentiel ces prochaines années:
- Les outils utilisés vont devenir de plus en plus simples et accessibles ;
- Les générations qui arrivent sur le marché du travail vont devenir de plus en plus familier aux concepts et outils ;
- La Data va être de plus en plus un sujet pour chaque département. Il est probable qu’il y ait à terme des squad Data au sein de chaque département.
Avant de rentrer dans le sujet, il est important de comprendre que le terme ‘Data’ regroupe souvent 2 notions, qui recouvrent deux types de métiers (en savoir plus sur la différence entre Data Analyst & Data Scientists)
Data Science / Machine Learning.
Les département Data Science ou Machine Learning se retrouvent principalement dans des entreprises dans lesquelles la Data a un rôle central dans le Produit.
Examples d’équipes Data Science ou Machine Learning:
Estimations de l’évolution de la capacité de batterie au fil des charges chez Tesla.
Calculs la rémunération des artistes chez Soundcloud.
Evolution des prix chez Amazon.
Data Analysis
Utilisation des données métiers de plusieurs sources (Sales, Customer Success, Produit, Marketing, Support) à des fins de prises de décisions Business.
Dans cet article, nous nous intéressons uniquement à la partie Data Analysis.
Cette pratique repose sur la construction d’une Stack Data (appelée souvent “Modern Data Stack” en anglais, et décrite plus tard).
Une Stack Data permet de:
- Améliorer la qualité des analyses en combinant des données de sources différentes (comme combiner des données du CRM avec des données du Support) ;
- Gagner un temps significatif dans la Production d’analyses en automatisant le Reporting en s’affranchissant des exports manuels et des Excels & Google Sheets ;
- Au sein de la société, l’accès à une donnée homogène (Single Source of Trust) permet d’aligner tout le monde sur les chiffres.
La prise de décision plus rapide et davantage basées sur des données.
Si le sujet vous intéresse, voici un autre article Tribes sur Comment choisir sa gouvernance et sa stack de data-analytics ? avec des exemples chez Partoo & ManoMano.
Modern Data Stack: Kézako?
Vous avez peut-être déjà entendu le terme “Stack Data”. Cela recouvre l’ensemble des outils mis en place pour manipuler les données utilisées à des fins de Data Analysis.
Pour bien comprendre, le plus simple est de partir du chemin de la Data: depuis sa création jusqu’à son utilisation.
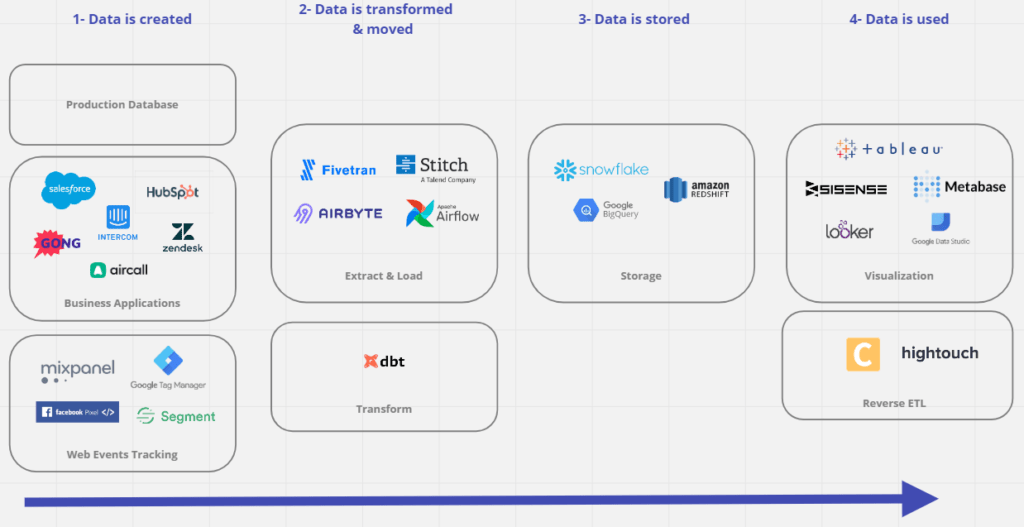
Etape 1: Créer la data
Evidemment, la première étape dans la vie de la “Data” est sa création.
La Data peut être créée à plusieurs endroits mais on voit bien souvent 3 types:
Product Database:
Il s’agit de la base de donnée de production (principalement dans le logiciel). C’est la base de donnée qui stocke l’ensemble des informations des plateformes des clients.
Par exemple, si vous êtes une société qui édite un CRM, vous allez avoir toutes les fiches Contacts pour chaque Client qui sont stockées dans cette base de donnée. Cette base de donnée va également contenir les informations d’abonnements si vous avez un produit self-service.
Dans la Product Database, ce sont les utilisateurs qui produisent de la donnée: à chaque action de la donnée nouvelle est produite.
Business Applications:
Il s’agit de l’ensemble des applications utilisées par les équipes métiers: Sales, Customer Success, Marketing, Product, etc. Ce sont ces équipes qui créent la donnée dans ces applications.
Dans le cas du CRM, toute la donnée qui est entrée par les équipes Sales & CSM y est stockée et peut être utilisée pour des analyses – ex. le Customer Health Score
Web Event Tracking:
Le tracking Web consiste à capturer les interactions sur un site Web: logiciel SaaS ou site internet.
Lorsqu’un “tracker” est installé, il va permettre de stocker les actions des utilisateurs.
Par exemple, le “tracker” enregistrera chaque visite d’une URL (ex: vue de la page ‘www.super.com/page1‘’), mais aussi les clicks sur des éléments web (ex: click sur l’élément HTML ‘CTA’ d’une page donnée). C’est l’usage des produits Web par les visiteurs et utilisateurs qui produit la donnée.
Etape 2: Transfomer et déplacer la Data
Cette partie s’appelle en anglais “ETL” pour “Extract Transform & Load”
- Extract & Load (E & L) correspondent à l’action de déplacer la donnée d’un point A à un point B.
En l’occurrence depuis par exemple l’application métier (comme un CRM, par exemple Salesforce) vers un Data Warehouse utilisé pour le stockage.
Pour réaliser cela, il est possible d’utiliser des programmes Open Source (type Apache Airflow ou Airbyte) qui vont nécessiter du développement et de la maintenance, ou bien des outils spécialisées qui construisent et maintiennent les différentes intégrations (comme Stitch ou Fivetran), mais qui sont payants et ne permettent pas d’avoir la main sur le format des données ; - Tranform (T) correspond à l’action de changer le format de la donnée. La donnée chargée depuis les applications métiers vers la Data Warehouse ne sont généralement pas au format désiré.
A l’aide de requêtes, il est possible de transformer la donnée directement dans le Data Warehouse.
Cependant, lorsque les transformations sont plus complexes et ne peuvent pas être réalisées avec des requêtes, il est possible d’utiliser des programmes spécifiques (type GetDbt).
La Transformation de la donnée nécessite des compétences spécifiques, et l’installation d’un environnement de développement et cette partie est donc moins accessible pour des débutants.
Etape 3: Stocker la Data
La donnée est ensuite généralement stockée dans une “Data Warehouse” (base de donnée hébergée dans le cloud).
Avec le développement du Cloud ces dernières années, ouvrir et utiliser un Data Warehouse est devenu très simple, rapide et assez peu coûteux.
Les principales solutions utilisées par les équipes Data en start-up sont:
Google BigQuery présente l’avantage (de réputation) d’être peu cher pour le stockage car le coût dépend essentiellement des calculs. Or les calculs, dans la plupart des start-ups, sont peu complexes (à l’exception des sociétés B2C ou des sociétés qui par nature manipulent de gros volumes de données.)
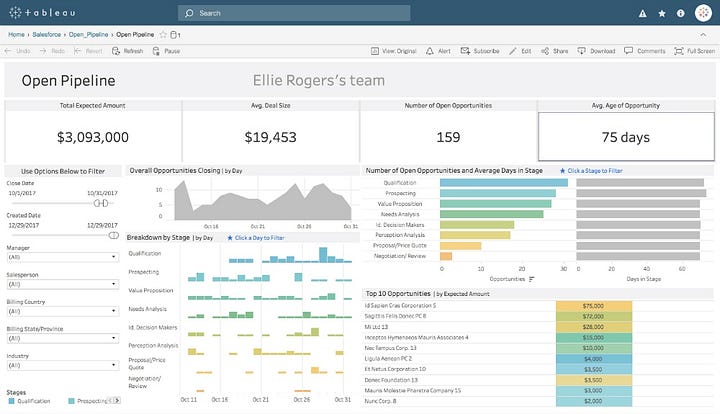
Pour rendre la chose plus visuelle, voilà à quoi ressemble l’écran principal de BigQuery de notre Data Warehouse chez AssoConnect:
- L’écran central permet de rédiger une requête SQL (Query editor).
- Sur le coté, on retrouve notamment l’historique des requêtes effectuées.
- En bas à gauche, la liste des “projets”. Chaque projet contient des ‘tables’ de la base de donnée. Dans notre cas, nous avons des projets pour nos différents connecteurs (Fivetran, Stitch, Segment), ainsi qu’un projet pour nos Analytics avec les “views” que nous utilisons.
Les “views” sont un outil puissant de BigQuery qui permet, par le biais d’une requête SQL, de maintenir en permanence (live) le résultat de la requête. Cela permet donc des transformations des tables sources sous un format exploitable pour les outils de visualisation.
Etape 4: Visualiser la Data
La Visualisation permet – comme son nom l’indique – de visualiser les données sous des formats décidés.
La Visualisation de la Data consiste donc à représenter sous forme de charts (bar chart, line chart, pie chart,…), de tableaux, scorecards, etc. les données obtenues afin de les rendre plus facilement interprétables.
Les outils de visualisation sont nombreux : il existe des outils gratuits, open source (Google Data Studio, Metabase) mais aussi de nombreux outils payants plus ou moins chers (Tableau, Sisense, Looker, ou Toucan Toco si vous voulez acheter français).
Ces outils se connectent généralement nativement (sans avoir à développer quoi que ce soit) directement à votre Data Warehouse (surtout si vous utilisez un de ceux cités précédemment). Ainsi en quelques secondes l’outil de visualisation est connecté au Data Warehouse.
A noter que les outils de Visualisation se connectent plus rarement directement aux applications métiers. C’est le cas par exemple de Salesforce pour Tableau (Salesforce ayant racheté Tableau, cela semble plutôt logique).
Les outils de visualisation se mettent à jour en temps réel (ou bien par période si on le souhaite), et se mettent donc à jour automatiquement lorsque la donnée sous jacente (stockée dans le Data Warehouse) évolue.
Etape 4bis (Bonus): Reverse ETL
Le Reverse ETL est une nouvelle catégorie d’outil qui a émergé récemment.
Il permet de faire le chemin inverse de l’ETL présenté plus haut. Une fois la donnée stockée dans la Data Warehouse, le reverse ETL permet de renvoyer des informations vers les applications métier, sans avoir à coder de connecteur spécifique.
Par exemple, le Reverse ETL va vous permettre de renvoyer une information depuis la Data Warehouse vers votre CRM.
Ainsi vous pouvez par exemple:
- Importer les données du CRM et de l’outil de Support dans la Data Warehouse ;
- Croiser ces informations (sur par exemple l’e-mail) pour connaitre le nombre de tickets créés par Client ;
- Retraiter l’information à l’aide de requêtes ;
- Renvoyer l’information souhaitée directement dans le CRM, dans la fiche profil de chaque contact.
Les métiers dans une équipe Data en start-up

Une fois que vous avez compris le chemin de la Data, il est beaucoup plus facile de se représenter les différents métiers d’une équipe Data.
Dans une équipe Data en start-up, on voit généralement 3 types de compétences.
Certains profils parviennent à être compétent sur chacun des métiers, mais il n’est pas rare de voir une spécialisation dans un domaine.
Data Engineer
La/le Data Engineer intervient principalement sur la partie amont du chemin de la Data, et notamment sur la partie “Extract Transform & Load”.
La/le Data Engineer est responsable de créer et de maintenir la stack Data dans son ensemble (création du Data Warehouse, administration) mais aussi d’assurer que les données arrivent dans le Data Warehouse au format désiré.
En schématisant, ils sont responsable du “chemin de la donnée” jusqu’à ce que celle-ci arrive au Data Warehouse, où elle sera manipulée par les Data Analysts.
Data Analyst
La/le Data Analyst intervient à la fin du chemin de la Data. Ce rôle consiste essentiellement à produire les Visualisations à partir des données du Data Warehouse.
Il est donc important que cette personne comprenne bien les enjeux métiers et les objectifs qui doivent être atteints grâce à la création des visualisations qui doivent être réalisées.
Data Scientist
La/le Data Scientist recouvre plusieus types de domaines d’expertises, notamment les rôles de “Machine Learning Engineer”.
En général la/le Data Scientist est une personne qui manipule des données avec l’objectif de trouver une réponse à une question donnée.
Ils utilisent souvent des modèles pour comprendre des phénomènes grâce à la donnée, ou bien pour réaliser des prédictions. .
Vous pouvez, pour plus de détail, consulter l’article de Welcome to the Jungle sur les métiers d’une équipe Data.
A qui une équipe Data en start-up doit-elle reporter?
Aujourd’hui, les département Data (en start-up) sont le plus souvent rattachés aux équipes techniques (Produit ou Engineering)
Avantages
Il y a plusieurs avantages à cela:
- Les équipes Data se basent souvent sur les données de “Production” qui sont la responsabilité des équipes Tech & Product. Cela permet donc un meilleur alignement quand il y a des modifications d’architecture ;
- Les compétences techniques développées par des équipes Data sont plus proches avec les équipes Tech & Product qu’avec les équipes Business. Cela permet donc d’assurer des échanges plus fluides.
- La façon de travailler est souvent plus proche avec les équipes Tech & Product qu’avec les équipes Business. La notion par exemple de “maintenance” est très présente en Data. Tout ce qui est construit doit être maintenu, comme du code.
Ce sont des notions qui sont souvent moins familières à des équipes Business, même si on retrouve cela en Revenue Operations (customisation du CRM par exemple).
Inconvénients
Il y a aussi quelques inconvénients mais le principal est le manque de proximité avec le Business. Cela peut conduire le département Data à travailler sur des sujets qui rejaillissent moins sur le reste de la société. Les équipes Data sont aussi moins concernées par les problématiques des départements Business (Sales, Marketing, CS, Support).
Il peut donc arriver que les sujets choisis n’apportent pas tous autant de valeur que possible.
Autres possibilités
Il est cependant possible d’imaginer de nombreux autres setup:
- Reporting au CEO: ce setup est approprié quand la société à des enjeux Data très élevés et un profil de Head of Data très senior et autonome.
- Reporting à la fonction Business Operations: ce setup peut très bien fonctionner mais nécessite d’avoir des profils assez senior au département BizOps, ce qui est encore assez rare dans les start-up françaises. Il faut aussi que la personne en charge des BizOps ait une appétence forte pour ces sujets.
Le bénéfice principal est un focus fort sur les aspects Business de la Data ce qui permet bien souvent d’éviter que les ressources soient trop focalisées sur un seul département. - Reporting à la Finance: fonctionne si la Finance a une composante Business Operations forte.
- Reporting au Revenue (CRO, VP Sales): cela doit s’apprécier en fonction des compétences et appétences de la personne en charge du Revenue.
Bénéfices de la “Modern Data Stack” et cas d’usages
Data Warehouse: quels avantages?
Combiner des données
Combiner des données provenant de plusieurs sources différentes. Lorsque l’on veut par exemple croiser de la donnée provenant CRM avec de la donnée provenant du logiciel de Support, cela peut vite devenir manuel et fastidieux.
Quand cela est possible, utiliser une intégration native est une bonne solution. Par exemple Zendesk s’intègre dans Hubspot ou Salesforce.
En revanche, cela n’est pas toujours possible, et le format de l’intégration peut être contraignant et ne pas permettre les cas d’usages souhaités.
Avec une Data Warehouse, vous pourrez facilement faire une jointure entre le CRM et l’outil de Support (s’il est possible bien sur de trouver un élément commun entre les deux sources de données, comme l’e-mail).
“Single Source of Trust”
L’utilisation d’un Data Warehouse permet d’homogénéiser la donnée utilisée au sein de la société. Cela permet de s’assurer que tout le monde utilise les même chiffres et les même définitions.
Cela permet bien souvent de gagner énormément de temps et de permettre aux équipes Business de discuter des sujets de fonds plutôt que de la façon dont ils ont calculé tel ou tel KPI.
Construire des visualisation avancées.
En tant que BizOps, on s’appuie beaucoup sur les Reports & Dashboards disponibles dans les CRM.
Les visualisations sont souvent limitées.
Sur Hubspot, il est complexe d’obtenir exactement ce que l’on souhaite et les Report sur plusieurs objets sont peu maniables — sur Salesforce l’ergonomie est limitée.
Construire des visualisations sur un outil de BI (Business Intelligence) permet de se rapprocher de la flexibilité qu’offre Excel ou Google Sheets, sans avoir à mettre à jour manuellement.
Automatiser des analyses.
Lorsque la Data Stack est construite, les visualisations se mettent à jour soit en temps réel, soit de façon automatisées (schedule).
Cela permet donc de ne pas avoir besoin de mettre à jour quoi que ce soit manuellement et c’est un gain de temps très appréciable.
Exemple d’utilisation: le Dashboard Client-Centric
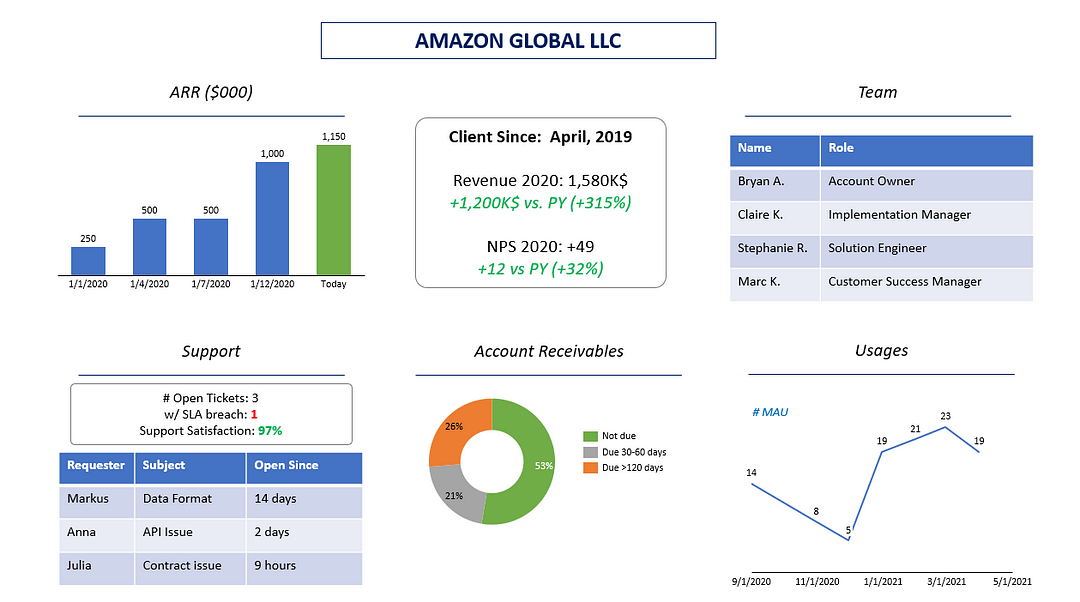
En utilisant plusieurs sources de données, il est possible de créer ce type de Dashboard qui combine par exemple des données:
- Financières: ARR, créances clients ;
- Commerciales: performance commerciale, renouvellement de contrats, etc. ;
- D’usage: NPS, Tickets de support, sessions, etc.
Il est par exemple possible, en utilisant des technologies l’Embedded Analytics (Tableau, Sisense, Looker, ou Toucan Toco en France), de créer un Dashboard-type et de l’inclure dans le CRM.
Ce Dashboard sera ainsi présent dans chaque fiche Client du CRM, évidemment filtré sur le Client en question, et mis à jour en permanence.
Combien coûte une stack Data pour une start-up?
Si vous n’êtes pas déjà à l’aise dans l’utilisation des outils Data, se lancer dans la construction d’une stack Data a un coût!

On peut dissocier:
- Le coût de setup: les dépenses que vous allez engager pour créer l’architecture Data, ainsi que chaque analyse ou Reporting.
- Le coût de maintenance: les dépenses récurrentes nécessaires pour que ce que vous avez construit continue de fonctionner dans le temps.
Les données que vous allez utiliser vont naturellement évoluer dans le temps et nécessiter de modifier les analyses et Reporting (plus souvent que vous pouvez l’imaginer).
Faire un choix
Ensuite, vous allez souvent devoir faire un choix entre Construire ou Acheter (Buy or Build en anglais):
- Construire: créer vous même les outils dont vous allez avoir besoin (exemple: des connecteurs maisons pour ne pas payer un ETL comme Fivetran qui est assez coûteux). Dans ce cas, il faut maintenir la solution dans le temps: la donnée va évoluer, il peut y avoir des disruption de service et donc des pertes de données, etc.
- Acheter: utiliser une solution logicielle déjà pré-construire pour votre besoin. Cela permet souvent d’aller plus vite et présente l’avantage que la maintenance soit faite essentiellement par l’éditeur. En revanche, il faudra souvent payer de façon récurrente.
Le plus souvent, il est préférable d’acheter – au moins au début — pour aller plus vite. Une fois que les besoins sont validés et si les coûts logiciels deviennent trop importants vous pouvez toujours reconstruire en interne.
Beaucoup de société ont tendance à construire d’abord, ce qui sur le long terme peut avoir un coût énorme en maintenance.
Les coûts
Les coûts de l’architecture Data dépendent beaucoup des volumes gérés, quelques ordres de grandeurs:
- Data Warehouse (stockage): quelques centaines d’euros par mois.
- ETL: à partir de 100$ par mois pour Stitch, et environ 1,000$ par mois pour Fivetran.
- Visualisation: gratuits pour Data Studio, Metabase, environ 700$ pour Tableau (package start-up) et 30K$+ pour Looker ou Sisense.
- Equipes: elles constituent souvent le coût principal, aussi bien les équipes Data que les équipes Engineering sollicitées.
> Data Analyst: 40K€-60K€ brut annuel (coût d’environ 350€ jour chargé)
> Data Engineer: 50K€-80K€ brut annuel (coût d’environ 500€ jour chargé)
> Consultant Data expérimenté: 700€-1,200€ / jour
Comment savoir si j’ai besoin d’une Stack Data dans ma start-up dés aujourd’hui?
L’accès aux données peut être un vrai problème qui créé beaucoup de frustration dans les équipes.
Il est donc facile de penser que la création d’une stack Data va résoudre tous les problèmes de données.

Cela peut cependant être un piège car la Data est un outil et non pas une solution en soit.
Partir du problème
Le plus important est systématiquement de partir de problèmes concrets et des bénéfices attendus.
Cela peut paraître évident, mais il est naturel de réfléchir à la solution, plutôt que de chercher à bien définir les problèmes.
L’objectif in fine est de créer de la valeur pour le Business, afin que le “ROI” (retour sur investissement) soit favorable pour l’entreprise.
Afin de déterminer si vous avez besoin d’une Stack Data aujourd’hui, il y a quelques questions que vous pouvez vous poser:
- Quelles sont les analyses que je ne peux pas réaliser aujourd’hui et que je pourrai faire avec une stack Data?
Quelle valeur ces analyses vont-elles m’apporter? - Combien de temps est passé chaque mois dans la préparation des Reporting & analyses diverses?
Par quelles personnes?
Combien je pense pouvoir faire gagner de temps à ces personnes en automatisant des Reporting?
Souvent, le besoin de créer une stack Data dépend de 3 facteurs:
- Quantité de données. Plus vous avez des données plus la mise en place d’une stack Data prend son sens.
Tout d’abord parce que manipuler des gros volumes avec Google Sheet ou Excel est vite difficile.
Mais aussi parce que pour faire des analyses intéressantes il faut avoir suffisamment de données. - Croissance & Ambitions. Dans les sociétés où la croissance est très rapide, ou si les ambitions sont très grandes, mettre en place une fonction Data rapidement semble pertinent.
Cela permet de promouvoir une culture de l’utilisation de la donnée dans la prise de décision. - Multiples applications. Si vous utilisez beaucoup de logiciels différents, mettre en place une Stack Data va vous permettre de centraliser beaucoup de donnée et de créer une ‘Single Source of Truth’ en interne. Cela permet aussi de croiser des données de plusieurs sources (exemple: CRM & Support).
Stack Data en start-up: par où commencer?
Se lancer dans la construction d’une stack Data peut sembler un gros défi

N’oubliez pas, vous n’avez pas besoin de construire quelque chose d’énorme tout de suite, et il est souvent préférable d’itérer.
Au début, il est préférable de se focaliser sur des quick wins.
Quelques idées pour commencer:
- Activer son réseau pour rencontrer des personnes qui l’ont fait. De plus en plus de sociétés se sont lancées dans cet exercice. Il devient plus facile d’avoir des retours d’expérience qui vont vous faire gagner beaucoup de temps ;
- Prendre des freelances au début. Il y a de nombreux freelances en Data sur des plateformes comme Malt ou Upwork. Vous pouvez très bien commencer par une première mission sur un besoin bien défini et avancer à partir de là.
- Recruter un Lead qui sait faire. Si vous ne connaissez pas le métier, et que vous avez de grosses ambitions pour cette fonction, n’hésitez pas à recruter quelqu’un qui a déjà mis en place une Stack Data par le passé. S’appuyer sur quelqu’un qui a l’expérience permet de gagner énormément de temps.
Conclusion
- Les sujets Data impressionnent souvent les non initiés, ce qui peut conduire à un cloisonnement du département Data. Cela est préjudiciable pour la création de valeur car la Data a besoin de collaborer avec les équipes Opérationnelles pour apporter toute sa valeur.
- Les problématiques Data sont de plus en plus imbriquées dans chaque fonction opérationnelle. Dans le futur, il va y avoir de plus en plus d’inégalité – avec d’une part des profils (ou entreprises) qui vont se familiariser aux sujets Data (en plus de leurs compétences métiers), et d’autre part des profils (ou entreprises) qui seront plus réticent à monter en compétence sur ces sujets. On le voit déjà très bien dans le Marketing Digital où la connaissance métier n’est plus suffisante pour être excellent.
- Les technologies modernes ont rendu beaucoup plus rapide, simple et accessible la création d’une Stack Data Moderne (“Modern Data Stack”) et il est donc possible de créer une architecture Data basique en quelques jours.
- Tout ce qui est construit par des équipes Data (requêtes, visualisation, connecteurs) nécessite va nécessiter du temps de maintenance. Cela peut être un réel piège: quand le temps nécessaire à la maintenance devient conséquent, il peut accaparer l’essentiel du temps de l’équipe Data. Il est donc important de rester centré sur les objectifs business et les problèmes que l’on souhaite résoudre, et ne pas hésiter à supprimer tout ce qui devient moins utile, au fil du temps.
N’oubliez pas: “Pour quelqu’un qui a un marteau, tout problème ressemble à un clou.”